1 2 3 4 5 6 string str1; string str2 ("abc" ) ; string str3 (4 , 'a' ) ; string str4 (str2, 1 ) ; string str5 (str2. begin(), str2. end()) ; cout << str2 << endl << str3 << endl<< str4 << endl<<str5<<endl;
1 2 3 4 5 6 7 8 string str1 ("str1" ) ;str1. append ("123" ); cout << str1 << endl; str1. append ("1230" , 2 ); cout << str1 << endl; string str2 ("str2" ) ;str1. append (str2, 0 , 1 ); cout << str2 << endl << str1 << endl;
1 2 3 4 str1123 str112312 str2 str112312s
1 2 3 4 5 string str1 ("string1" ) ;str1. erase (0 , 1 ); cout << str1 << endl; str1. erase (2 ); cout << str1 << endl;
1 2 3 4 5 string str1 ("string1string1" ) ;string temp = str1. substr (1 , 2 ); cout << temp << endl; string temp2 = str1. substr (1 ); cout << temp2 << endl;
1 2 3 4 5 6 7 string str1 ("124" ) ;cout << stoi (str1) << endl; cout << stof (string ("124.3" )) << endl; string str = to_string (124 ); cout << str << endl; str = to_string (13.4 ); cout << str << endl;
比较两个字符串。
1 2 char op[20 ];strcmp (op, "osne" );
相等,返回值为 0
前者大于后者,返回值为正数
前者小于后者,返回值为负数
推荐阅读:算法学习笔记(13): KMP算法
KMP 是一种字符串匹配算法,它可以在一个字符串(S)中找出所有另一个字符串(T)的出现。
如果是暴力匹配的话,遇到不匹配的一个字符,就得把T字符串相对S向右移动一位,同时将T指针归零,S指针与T对齐进行重新匹配,如下图:
但是这样极端情况下复杂度会达到 O ( n m ) O(nm) O ( n m )
KMP 算法中定义了一个 p m t pmt p m t p m t i pmt_i p m t i i + 1 i+1 i + 1 S 0 ∼ i S_{0\sim{i}} S 0 ∼ i 的 Border 长度 。
Border 为一个字符串前缀与后缀最长匹配的部分 ,例如 abacaba \text{abacaba} abacaba aba \text{aba} aba
所以每次匹配失败之后就可以把T串已经匹配的部分变为它的 Border,假如T串当前匹配到下标为i i i i − s t r l e n ( B o r d e r i ) + 1 i-strlen(Border_i)+1 i − s t r l e n ( B o r d e r i ) + 1
注意 Border 的长度不超过自身字符串的长度。
代码实现大概是这样的:
1 2 3 4 5 6 7 for (int i=0 ,j=0 ;i<s.length ();i++){ while (j&&s[i]!=t[j]) j=pmt[j-1 ]; if (s[i]==t[j]) j++; if (j==t.length ()) j=pmt[j-1 ]; }
举个例子,S = ABCABACABCAB , T = ABCAB S=\text{ABCABACABCAB},T=\text{ABCAB} S = ABCABACABCAB , T = ABCAB T T T p m t pmt p m t
p m t pmt p m t B o r d e r Border B o r d e r 0 0 1 0 2 0 3 1 4 2
然后进行匹配,设 i i i S S S j j j T T T i = j = 4 i=j=4 i = j = 4 i = 4 , j = 5 , j = p m t j − 1 = 2 i=4,j=5,j=pmt_{j-1}=2 i = 4 , j = 5 , j = p m t j − 1 = 2 i = 5 i=5 i = 5 A B AB A B j j j 1 1 1 j = l e n g t h t j=length_t j = l e n g t h t j j j p m t j − 1 pmt_{j-1} p m t j − 1 0 0 0
那么 p m t pmt p m t
相当于拿自己和自己进行匹配,代码如下。
1 2 3 4 5 6 for (int i=1 ,j=0 ;i<t.length ();i++){ while (j&&t[i]!=t[j]) j=pmt[j-1 ]; if (t[i]==t[j]) j++; pmt[i]=j; }
当然也有另一种写法,是存最长 Border 的右端点下标,记为 n x t i nxt_i n x t i
P3435
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <bits/stdc++.h> using namespace std;int n;char a[1000005 ];int nxt[1000005 ];long long ans;int main () scanf ("%d" ,&n); scanf ("%s" ,a); memset (nxt,-1 ,sizeof (nxt)); for (int i=1 ,j=-1 ;i<n;i++) { while (j>-1 &&a[i]!=a[j+1 ]) j=nxt[j]; if (a[i]==a[j+1 ]) j++; nxt[i]=j; } for (int i=1 ,j=1 ;i<n;i++) { while (nxt[j]>-1 ) j=nxt[j]; if (nxt[i]>-1 ) nxt[i]=j; ans+=i-j; j=i+1 ; } printf ("%lld" ,ans); return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <bits/stdc++.h> using namespace std;int n;char a[1000005 ];int pmt[1000005 ];long long ans;int main () scanf ("%d" ,&n); scanf ("%s" ,a); for (int i=1 ,j=0 ;i<n;i++) { while (j&&a[i]!=a[j]) j=pmt[j-1 ]; if (a[i]==a[j]) j++; pmt[i]=j; } for (int i=1 ,j=2 ;i<n;i++) { while (pmt[j-1 ]) j=pmt[j-1 ]; if (pmt[i]) pmt[i]=j; ans+=i-j+1 ; j=i+2 ; } printf ("%lld" ,ans); return 0 ; }
这道题解法就是对每个前缀找出它的最小 Border 的长度,然后拿当前前缀长度减去这个最小 Border 的长度,再把每个前缀的答案加起来就是最后的答案,细节见代码,有助于加深对 KMP 两种写法的理解。
P2375动物园
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #include <bits/stdc++.h> using namespace std;const int N=1e6 +10 ;const int mod=1e9 +7 ;int n;char a[N];int nxt[N],num[N];long long ans;int main () scanf ("%d" ,&n); while (n--) { scanf ("%s" ,a+1 ); ans=1 ; num[1 ]=1 ; int l=strlen (a+1 ); for (int i=2 ,j=0 ;i<=l;i++) { while (j&&a[i]!=a[j+1 ]) j=nxt[j]; if (a[i]==a[j+1 ]) j++; nxt[i]=j; num[i]=num[j]+1 ; } for (int i=2 ,j=0 ;i<=l;i++) { while (j&&a[i]!=a[j+1 ]) j=nxt[j]; if (a[i]==a[j+1 ]) j++; while ((j<<1 )>i) j=nxt[j]; ans=ans*(num[j]+1 )%mod; } printf ("%lld\n" ,ans); } return 0 ; }
先把所有的后缀数量和都求出来,这个可以通过递推关系求出,即s u m i = s u m n x t i + 1 sum_i=sum_{nxt_i}+1 s u m i = s u m n x t i + 1
然后再匹配处理一次,匹配的过程中的时候对于每一个j j j
Z 算法又被叫做扩展 KMP 算法,其核心是 Z 函数。图片来源
Z i Z_i Z i i i i
贴一张图:
特别地,令Z 0 = 0 Z_0=0 Z 0 = 0
假设Z i ≠ 0 Z_i\ne0 Z i = 0 [ i , i + Z i − 1 ] [i,i+Z_i-1] [ i , i + Z i − 1 ] Z-Box \text{Z-Box} Z-Box Z − B o x Z-Box Z − B o x
我们从左向右枚举i i i Z − B o x Z-Box Z − B o x l ≤ i l\le{i} l ≤ i
那么就有以下三种情况:
i > r i>r i > r Z − B o x Z-Box Z − B o x Z − B o x Z-Box Z − B o x i ≤ r i\le{r} i ≤ r l c p lcp l c p
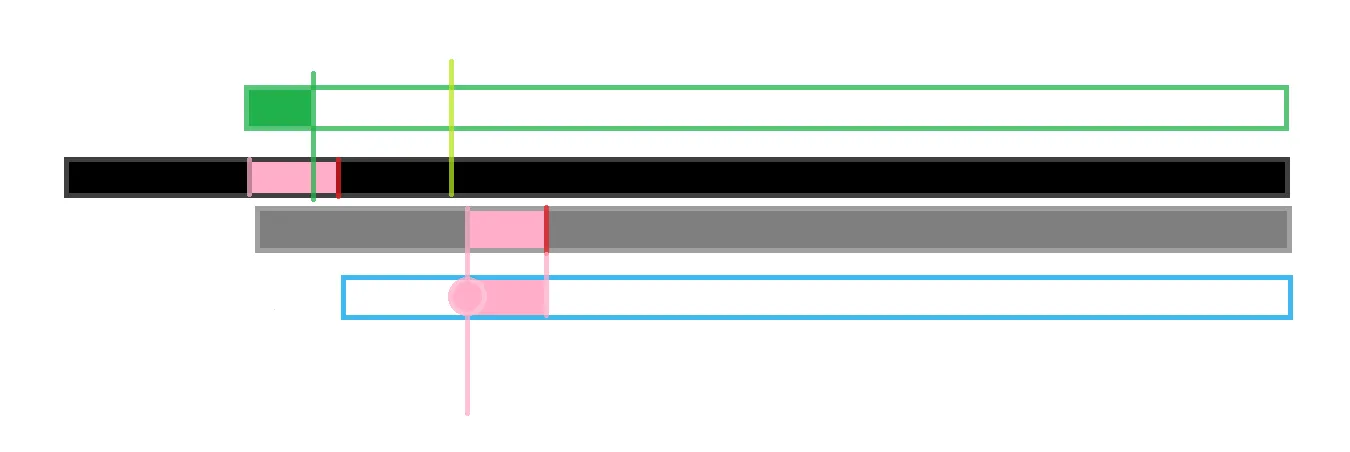
黑色为原序列,我现在要求每一个后缀与原序列的 lcp,即最大公共前缀。
比如我现在要求粉色点的 lcp,
但是发现这个点在当前最大lcp的右端点的范围内(红色线),即我们知道了灰色与黑色的 lcp,而灰色与蓝色的粉色部分又相同,于是蓝色和黑色的粉色部分也相同。
而对于粉色部分,我们已经知道了绿色与的 lcp,绿色<粉色,相同位置的绿色=粉色,于是绿色的 lcp 就可以被粉色点继承;假如绿色>粉色,但是超出部分在蓝色部分中不一定相同,因此最多能继承到粉色的边界处,因此绿色的 lcp的右端点下标要与粉色右端点下标取min \min min
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <bits/stdc++.h> using namespace std;char s[1000005 ];int n;int z[100005 ];int main () n=strlen (s); z[0 ]=n; for (int i=1 ,l=0 ,r=0 ;i<n;i++) { if (z[i-l]<r-i+1 ) z[i]=z[i-l]; else { z[i]=max (r-i+1 ,0 ); while (i+z[i]<n&&s[z[i]]==s[i+z[i]]) z[i]++; l=i,r=i+z[i]-1 ; } } return 0 ; }
注意 l , r l,r l , r
这个过程中,r r r r r r O ( n ) O(n) O ( n )
一种解决回文串问题的算法
回文串分为奇回文串和偶回文串,而偶回文串不存在固定的回文中心,因此就要进行一些处理,在字符间加上一些其他字符,比如#或者$。
奇回文串abcba = $a$b$c$b$a$ \text{abcba}=\text{\$a\$b\$c\$b\$a\$} abcba = $a$b$c$b$a$
这样对于一个偶回文串abccba \text{abccba} abccba $a$b$c$c$b$a$ \text{\$a\$b\$c\$c\$b\$a\$} $a$b$c$c$b$a$
设数组 d i d_i d i s i s_i s i 1 , 3 , … , 2 d i − 1 1,3,\dots,2d_i-1 1 , 3 , … , 2 d i − 1 O ( n ) O(n) O ( n )
而以 i i i d i − 1 d_i-1 d i − 1
Manacher 的思想与 Z 算法很像,都是维护了一个最远的右端点,不过在 Manacher 里维护的是右端点最大的奇回文串,
当枚举到一个 i i i
i > r i>r i > r d i d_i d i l , r l,r l , r i ≤ r i\le{r} i ≤ r r r r j j j j j j l l l d j d_j d j d i = d j d_i=d_j d i = d j 如果以 j j j l l l i i i j − l + 1 j-l+1 j − l + 1 r − i + 1 r-i+1 r − i + 1 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <bits/stdc++.h> using namespace std;int n;int d[1000005 ];char s[1000005 ];int main () for (int i=0 ,l=0 ,r=-1 ;i<n;i++) { int j=l+r-i; int dj=j>=0 ?d[j]:0 ; d[i]=max (min (dj,r-i+1 ),0 ); if (j-dj<l) { while (i-d[i]>=0 &&i+d[i]<n&&s[i-d[i]]==s[i+d[i]]) d[i]++; l=i-d[i]+1 ,r=i+d[i]-1 ; } } return 0 ; }
为了使自己本身也能被算上,所以初始 r r r
这个过程中,r r r r r r O ( n ) O(n) O ( n )
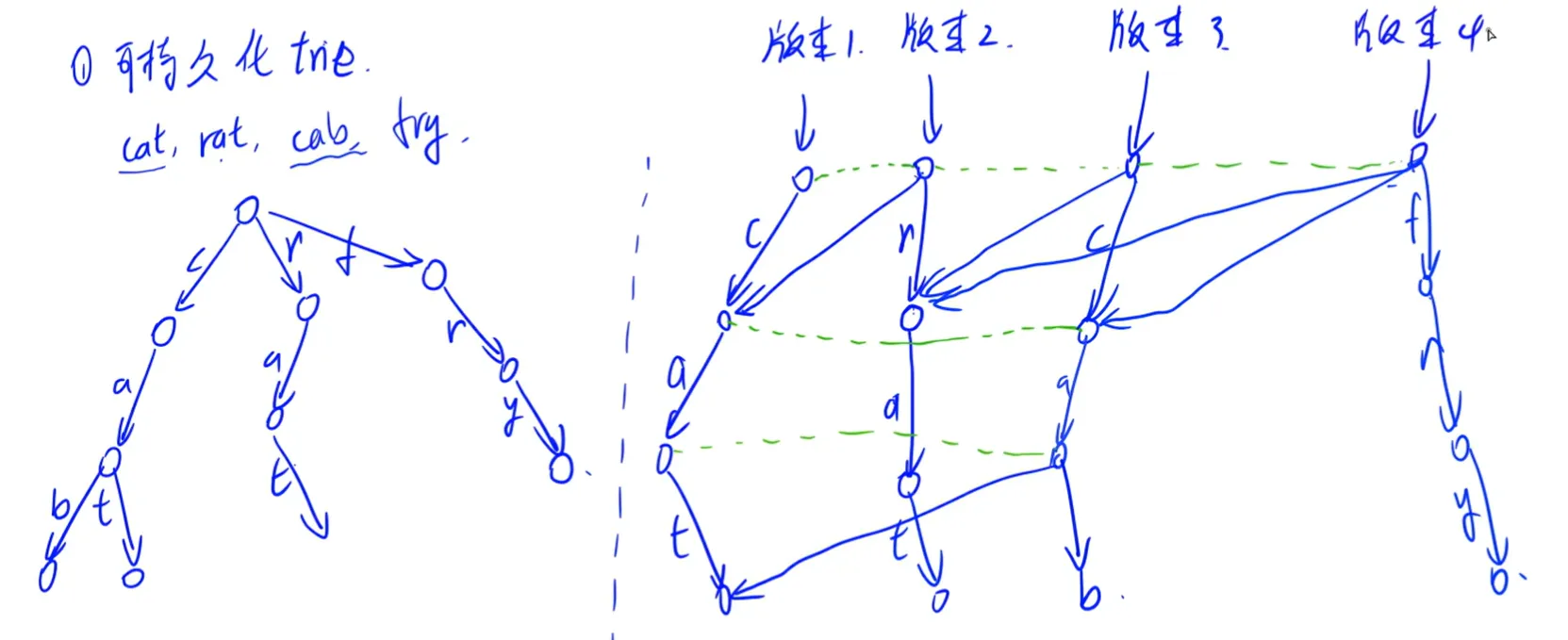
字典树,可以理解为 n n n n n n
模板:
P8306
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 #include <bits/stdc++.h> using namespace std;const int N=3e6 +10 ;int t,cnt=1 ;int nxt[N][80 ];int val[N];char a[N];void init (int x) for (int i=0 ;i<=x;i++) { val[i]=0 ; for (int j=0 ;j<=77 ;j++) nxt[i][j]=0 ; } cnt=1 ; } void insert (const string &s) int cur=1 ; for (auto &c:s) { if (!nxt[cur][c-'0' ]) nxt[cur][c-'0' ]=++cnt; cur=nxt[cur][c-'0' ]; val[cur]++; } } int query (const string &s) int cur=1 ; for (auto &c:s) { if (!nxt[cur][c-'0' ]) return 0 ; cur=nxt[cur][c-'0' ]; } return val[cur]; } int main () cin>>t; while (t--) { int n,q; scanf ("%d%d" ,&n,&q); for (int i=1 ;i<=n;i++) { string s; scanf ("%s" ,a); s=a; insert (s); } for (int i=1 ;i<=q;i++) { string s; scanf ("%s" ,a); s=a; printf ("%d\n" ,query (s)); } init (cnt); } return 0 ; }
例题:
P2580
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 #include <bits/stdc++.h> using namespace std;int n,cnt,q;char a[100 ];int nxt[1000005 ][26 ];int vis[1000005 ];void init () memset (nxt,0 ,sizeof (nxt)); cnt=1 ; } void insert (const string &s) int cur=1 ; for (auto &c:s) { if (!nxt[cur][c-'a' ]) nxt[cur][c-'a' ]=++cnt; cur=nxt[cur][c-'a' ]; } } int query (const string &s) int cur=1 ; for (auto &c:s) { if (!nxt[cur][c-'a' ]) return 0 ; cur=nxt[cur][c-'a' ]; vis[cur]++; } for (int i=0 ;i<26 ;i++) if (vis[nxt[cur][i]]) return 0 ; if (vis[cur]>1 ) return 1 ; return 2 ; } int main () scanf ("%d" ,&n); for (int i=1 ;i<=n;i++) { scanf ("%s" ,a); string s=a; insert (s); } scanf ("%d" ,&q); for (int i=1 ;i<=q;i++) { scanf ("%s" ,a); string s=a; int op=query (s); if (op==0 ) printf ("WRONG\n" ); else if (op==1 ) printf ("REPEAT\n" ); else if (op==2 ) printf ("OK\n" ); } return 0 ; }
对于属于修改的但是已有节点,复制粘贴。
对于不属于修改但是原来有的节点,直接连接(相当于复制粘贴的时候直接把属性复制了过来)。
对于属于修改的新节点,新建一个节点。
都是对于上一个版本的操作。
每次先得到上一个版本,然后开一个新的节点,把根节点先克隆过来。
然后遍历每个节点,如果有就复制粘贴,没有就新建。
AcWing256
怎么判断左界?
记录一下每个节点的子树里的下标最大值即可。
怎么判断右界?看第 r r r
前缀和处理:
a n s = s N ⊕ s p − 1 ⊕ x ans=s_N\oplus{s_{p - 1}}\oplus x a n s = s N ⊕ s p − 1 ⊕ x
于是我们在 l ∼ r l\sim r l ∼ r p − 1 p - 1 p − 1 l − 1 ∼ r − 1 l-1\sim r-1 l − 1 ∼ r − 1 p p p