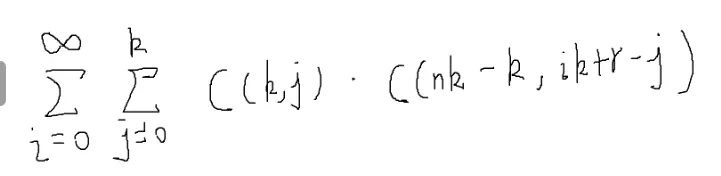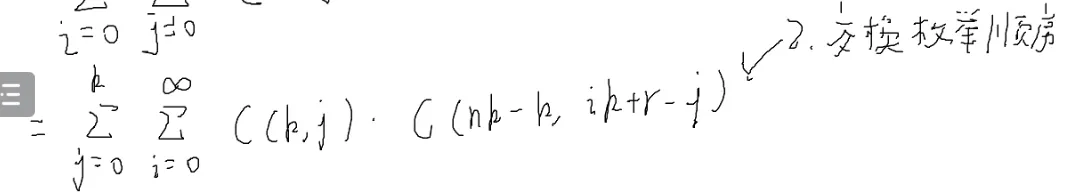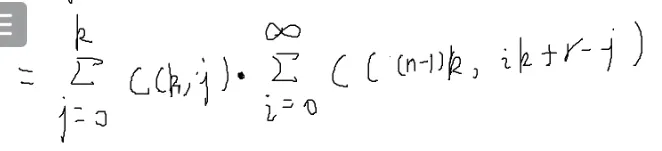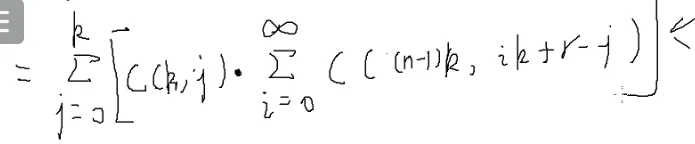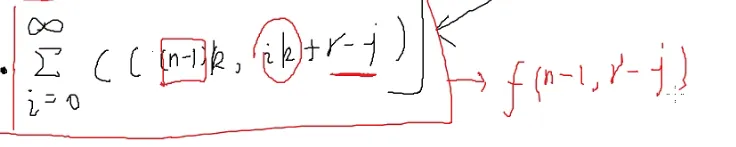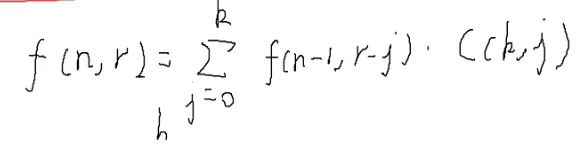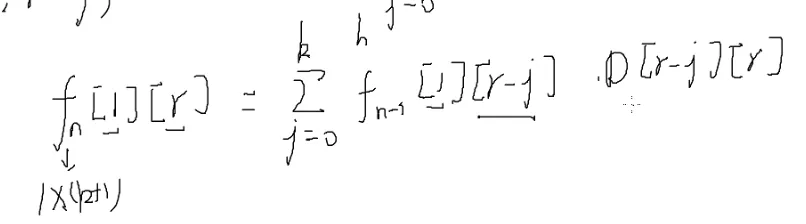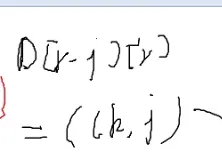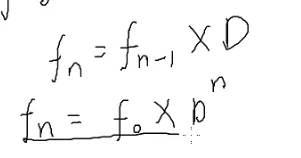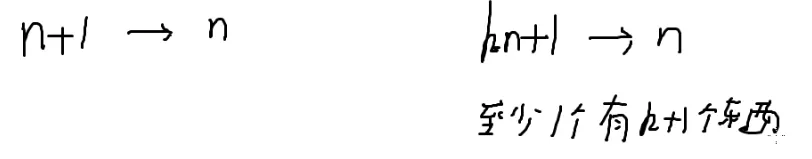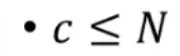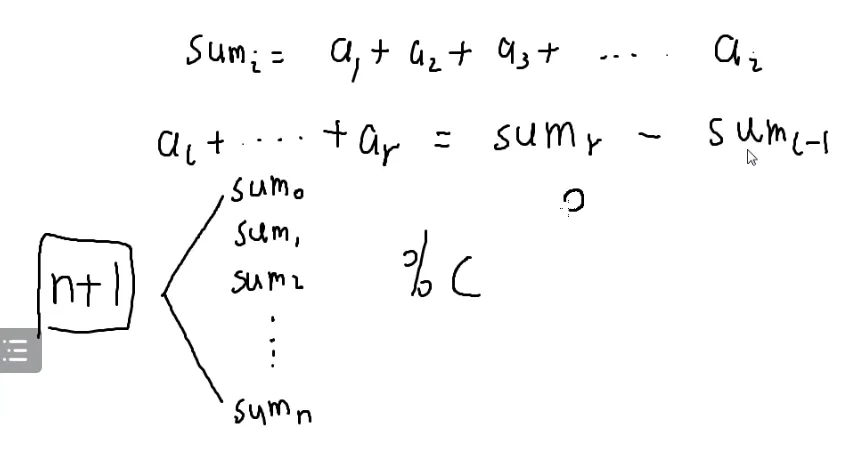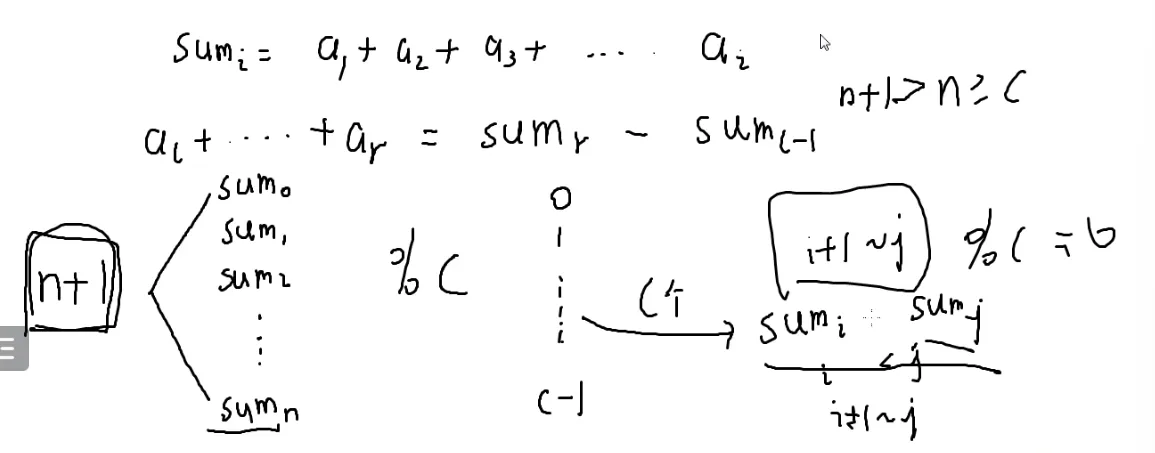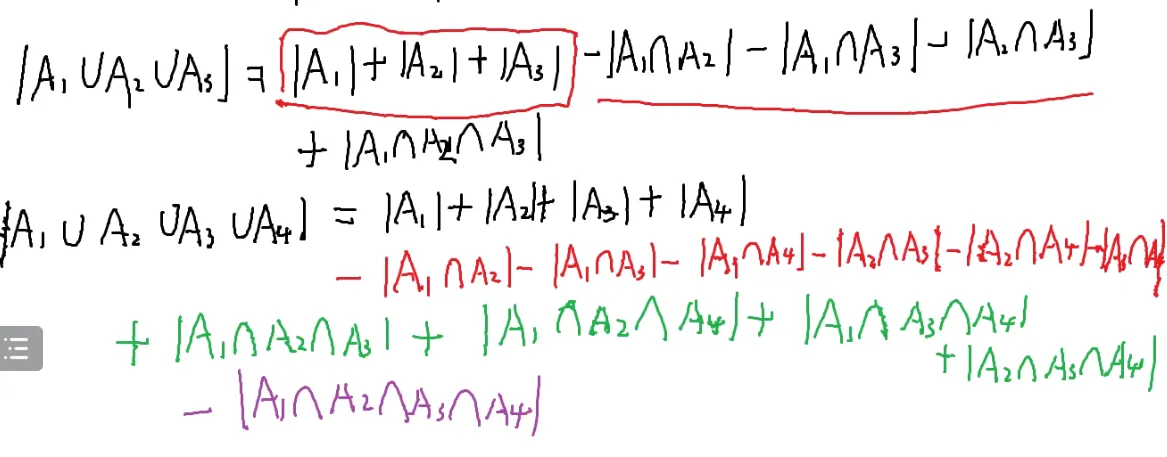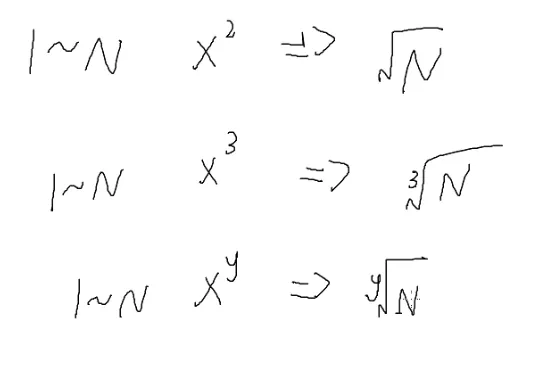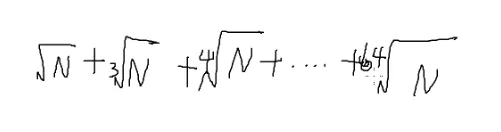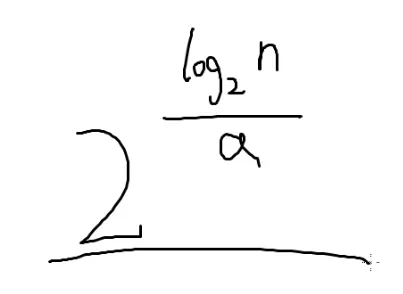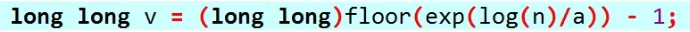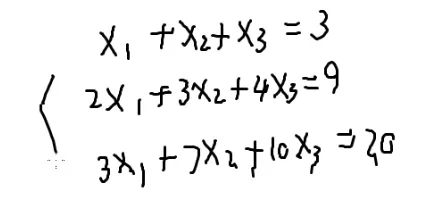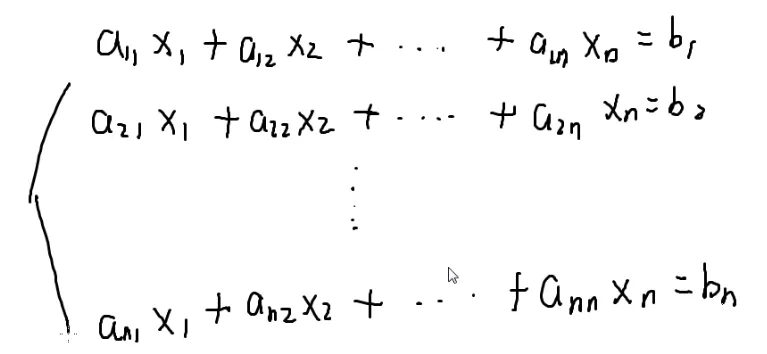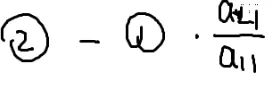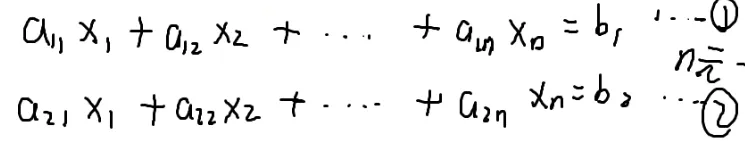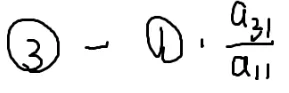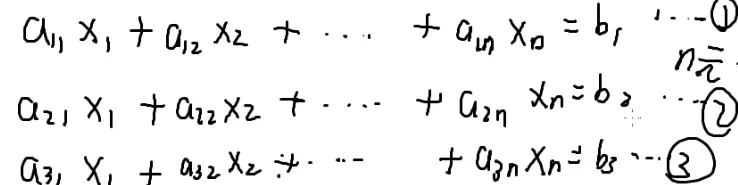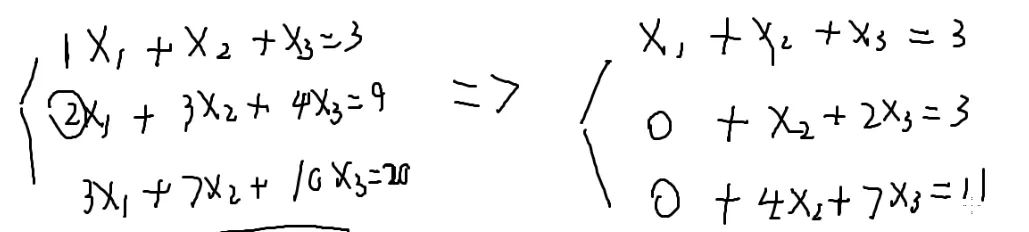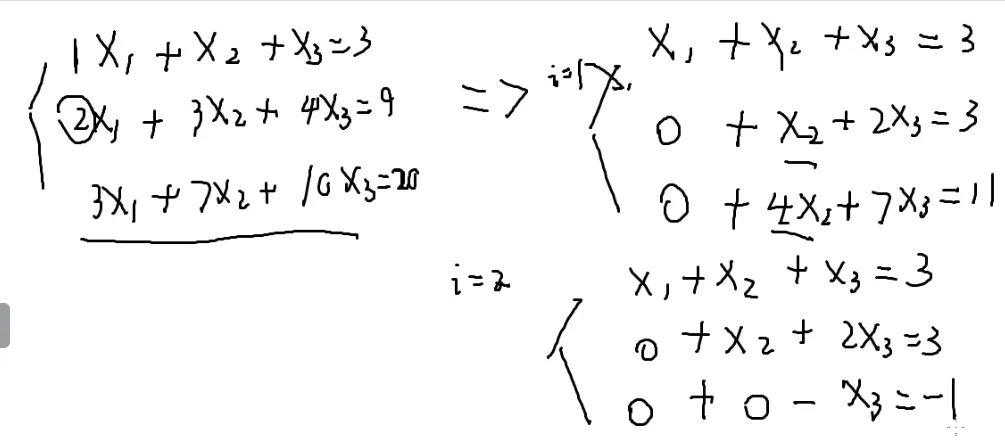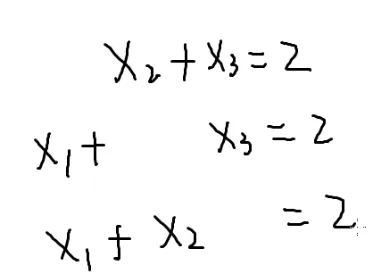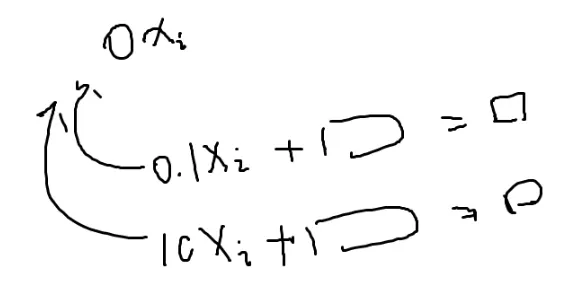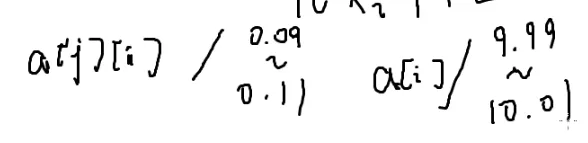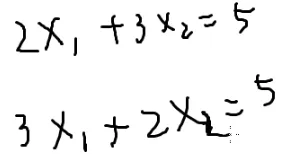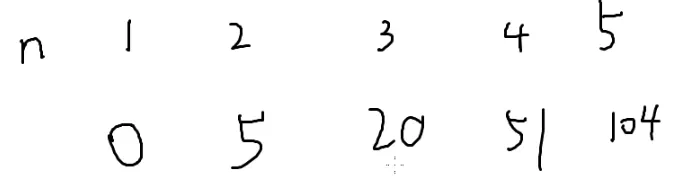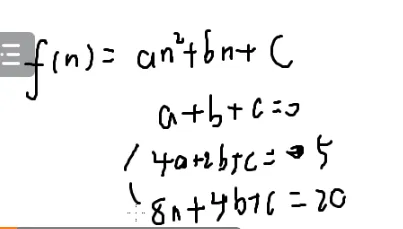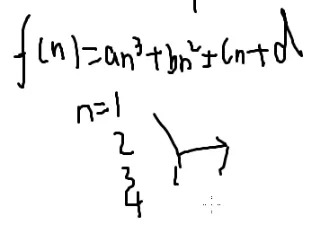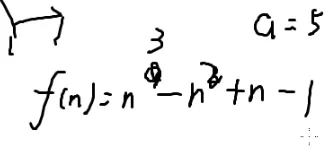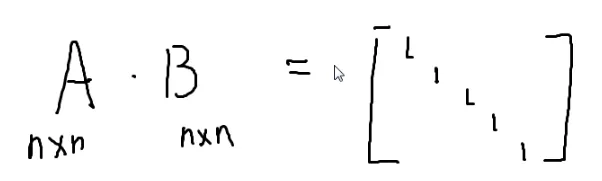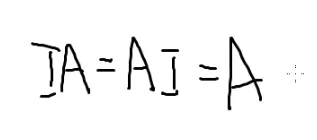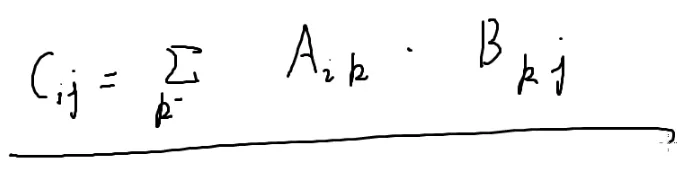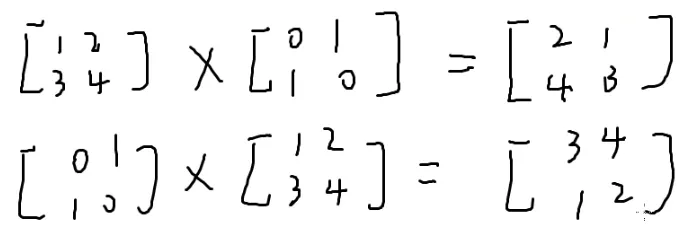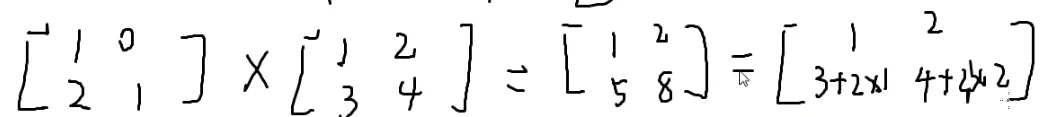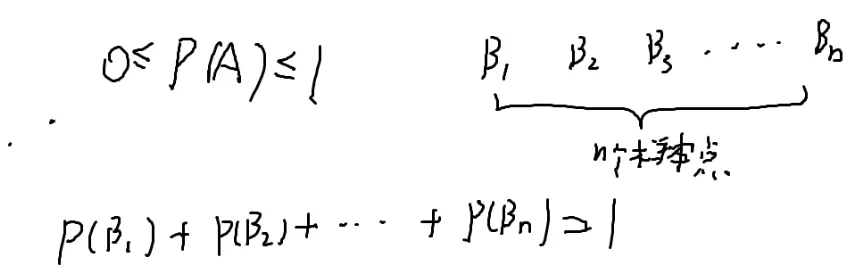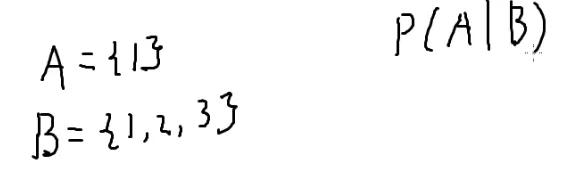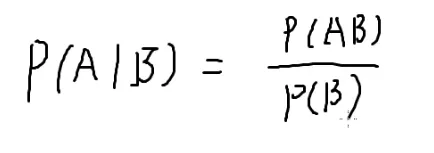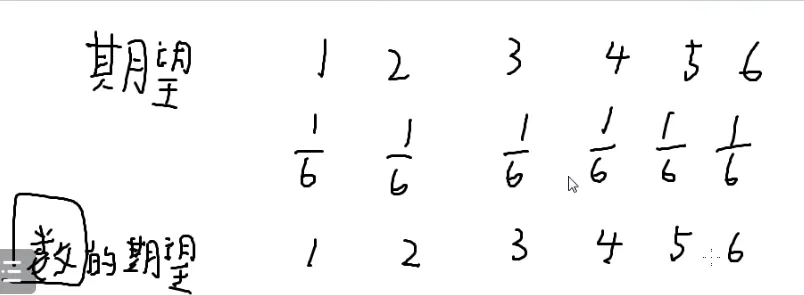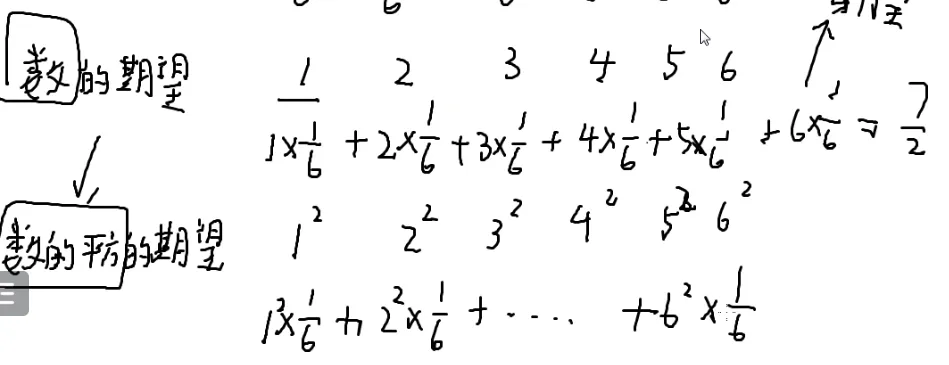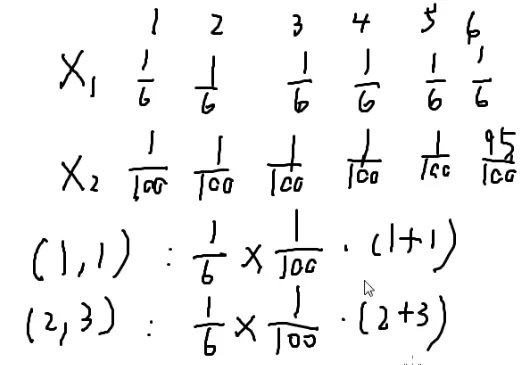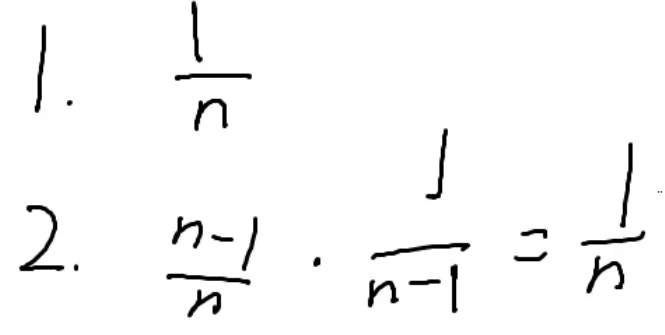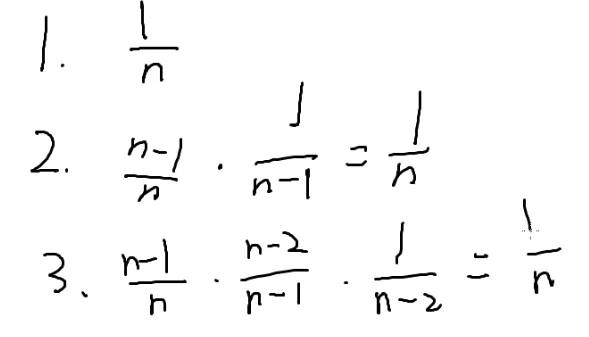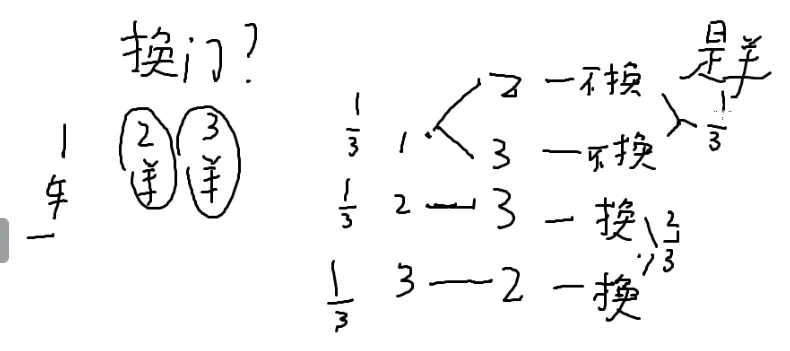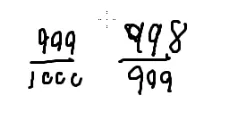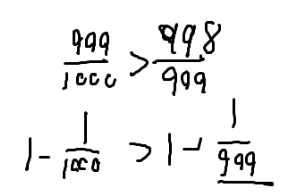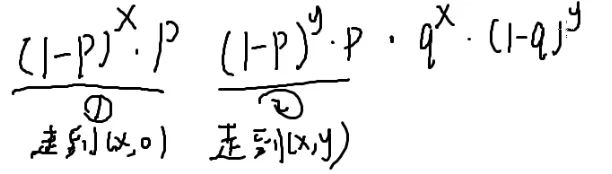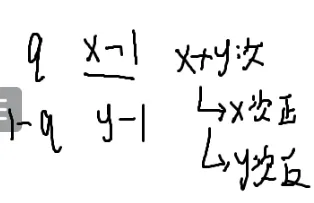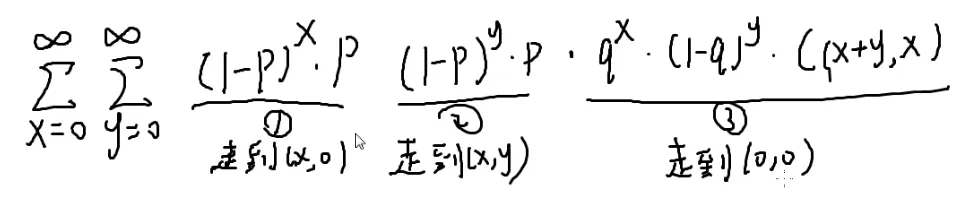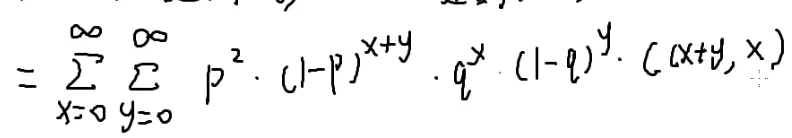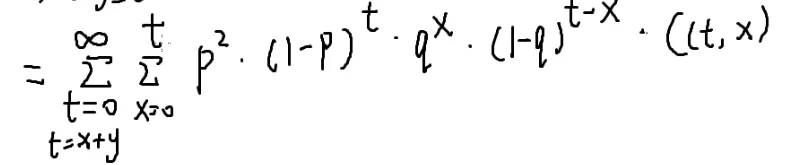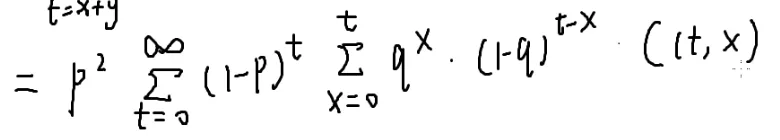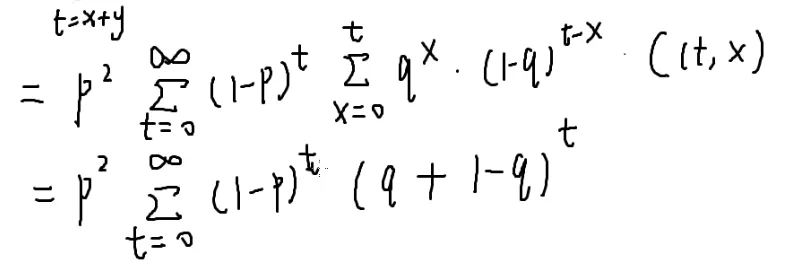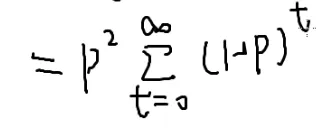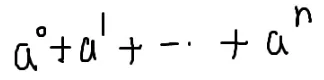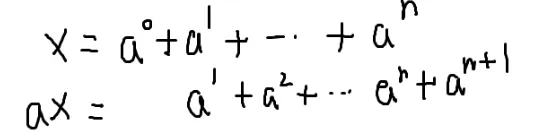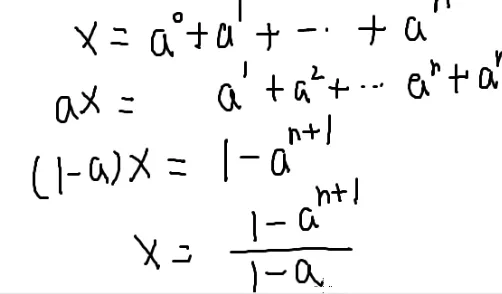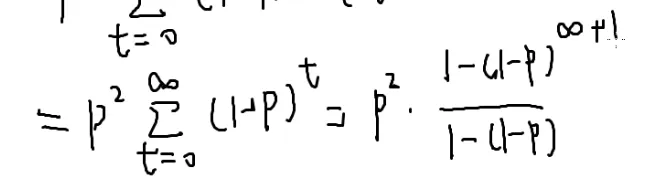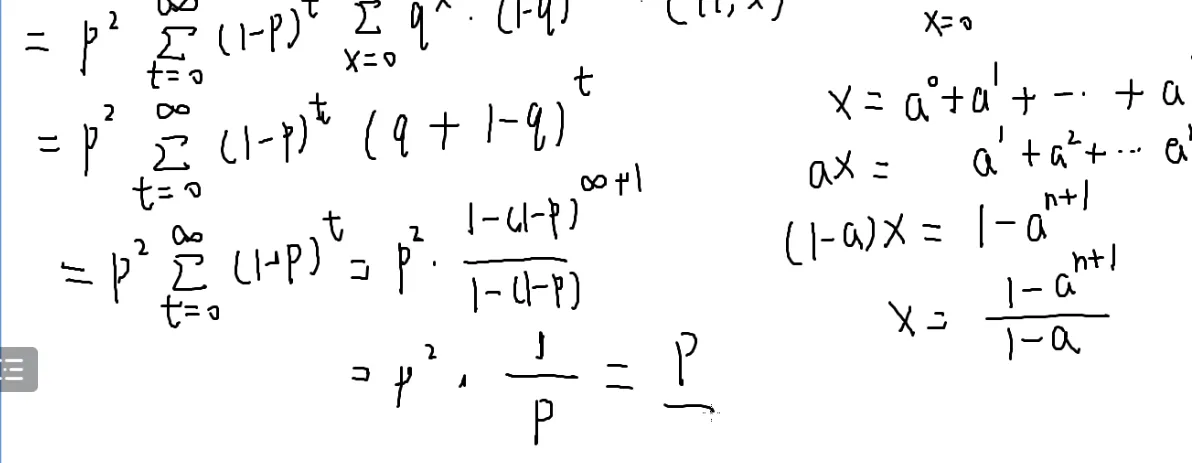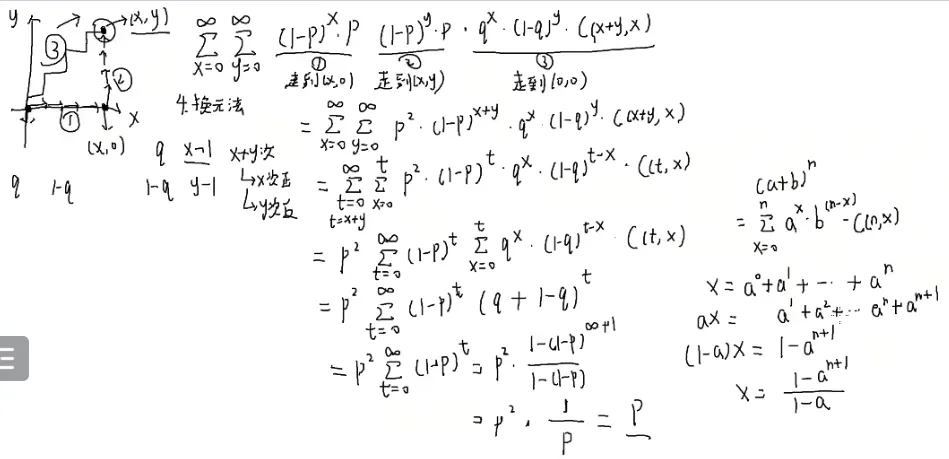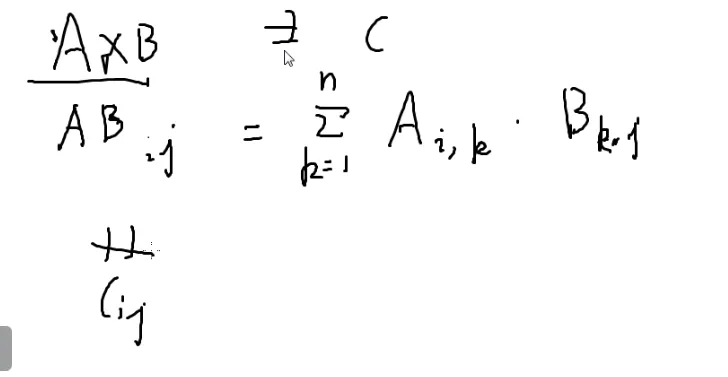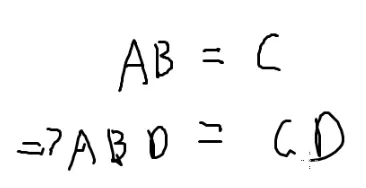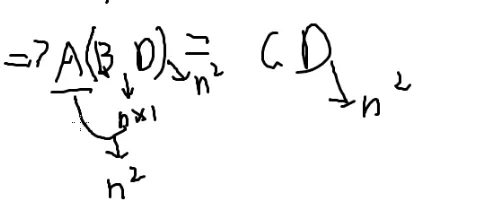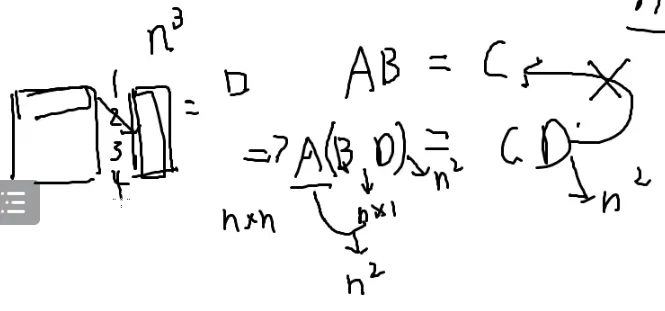基础数学
取模
一张图搞懂取模:

1
2
3
4
5
6
| int a,b,c;
cin>>a>>b>>c;
cout<<(a+b)%c<<endl;
cout<<((a-b)%c+c)%c<<endl;
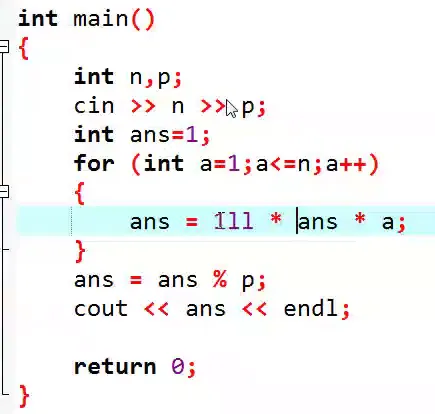
cout<<(1ll*a*b)%c<<endl;
cout<<((long long)a*b)%c<<endl;
|
数学和计算机中的取模实现方式不同,对于正数,两种方式得到的答案一样,但是对于负数却不同。
对于下面例子:
−3mod2
数学得到的答案是:−3−⌊−3/2⌋×2=1
计算机得到的答案是:−3−(−3/2)×2=−1
故计算机对负数取模的时候,需要 ((−3mod2)+2)mod2
通过规律我们发现,当被模数为正数时,答案是非负数;模数为负数时,答案是非正数。
阶乘
n的阶乘:
n!=n×(n−1)×(n−2)×…×1
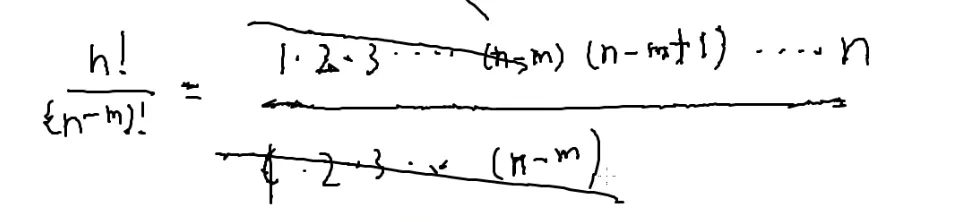
n!%p
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| #include<bits/stdc++.h>
using namespace std;
int main()
{
int n,p;
cin>>n>>p;
int ans=1;
for(int i=1;i<=n;i++)
{
ans*=i;
ans%=p;
}
return 0;
}
|
典型的错误写法:
GCD&LCM
太熟悉了
求一下gcd
设gcd(a,b)=g
整除:g∣a g 能整除 a a(modg)=0
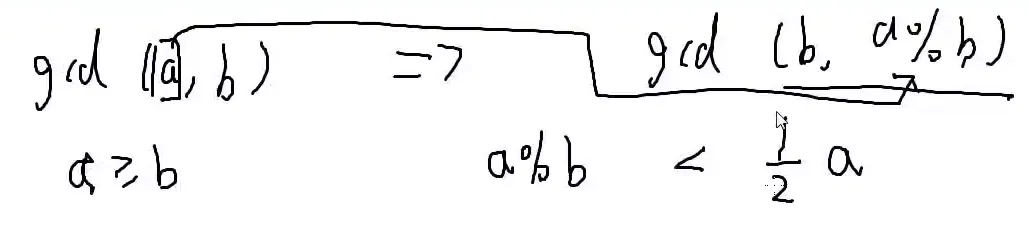
gcd(a,b)=gcd(b,a%b)
1
2
3
4
5
| int gcd(int a,int b)
{
if(b==0) return a;
return gcd(b,a%b);
}
|
1.b≤2a时,a%b≤2a
wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwww
2.b≥2a时,a%b=a−b≤2a
所以a%b<21a
复杂度?
1
2
3
4
5
6
7
8
| int n;
cin>>n;
for(int i;i<=n;i++)
cin>>a[i];
int ans=a[1];
for(int i=2;i<=n;i++)
ans=gcd(ans,a[i]);
cout<<ans<<endl;
|
O(n+logamax)
ans只会不断变小
除2的次数只有log次
若gcd(a,b)=g,lcm(a,b)=l
l=a∗b/g
小寄巧:a∗b/gcd(a,b)→a/gcd(a,b)∗b
先除后乘防止爆
快速幂
xy%p
朴素的代码:
1
2
| for(int i=1;i<=y;i++)
ans=1ll*ans*x%p;
|
比如现在要算x37
需要乘36次
x37=x182⋅x
时间复杂度就是O(logn)
可以递归求解
朴素的代码:
1
2
3
4
5
6
7
8
| int ksm(int x,int y,int p)
{
if(y==0) return 1;
int z=ksm(x,y/2,p);
z=1ll*z*z%p;
if(y%2==1) z=1ll*z*x%p;
return z;
}
|
优化
位运算: if(y&1) z=1ll*z*x%p;
1
2
3
4
5
6
7
8
9
10
11
12
| typedef long long ll;
ll ksm(ll x, ll y)
{
ll res = 1;
while(y > 0)
{
if(y & 1) res = res * x % p;
x = x * x % p;
y >>= 1;
}
return res;
}
|
小题目:x,y,p,算x∗y%p
快速乘法
1
2
3
4
5
6
7
8
| int kscf(int x,int y,int p)
{
if(y==0) return 0;
int z=kscf(x,y/2,p);
z=(z+z)%p;
if(y&1) z=(z+x)%p;
return z;
}
|
矩阵
n行m列的一个东西
两个矩阵做加法的条件是两个矩阵的大小一样
做法:
对应位置的数字加起来
减法同理:
数乘:
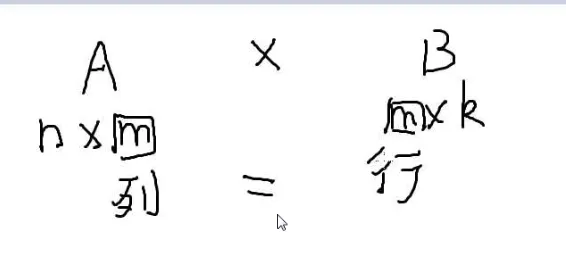
矩阵乘法:
⎣⎡147258369⎦⎤
[1324]×[122333]=[511818921]
第一个的列数 = 第二个的行数
第一行第一列,取出第一个的第一行,第二个的第一列
一一相乘再相加
代码实现:
1
2
3
4
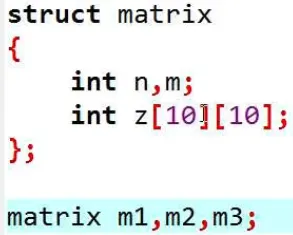
| struct matrix{
int n,m;
int z[23][23];
}
|
z数组不一定为0(受很多因素影响)
构造函数
1
2
3
4
5
6
7
8
| struct matrix{
int n,m;
int z[23][23];
matrix()
{
memset(z,0,sizeof(z));
}
};
|
重载运算符
不会影响正常的∗
1
| matrix operator*(matrix m1,matrix m2)
|
这样写有没有什么问题?
涉及到一个传参的问题:
为了避免占空间,可以这样写:
1
| matrix operator*(matrix &m1,matrix &m2)
|
为了避免算出结果以后原值被修改,可以这样写:
1
| matrix operator*(const matrix &m1,const matrix &m2)
|
接下来是矩阵乘法的函数内容了
1
2
3
4
5
6
7
8
9
10
11
| matrix operator*(const matrix &m1,const matrix &m2)
{
matrix m3;
m3.n=m1.n;
m3.m=m2.m;
for(int i=1;i<=m3.n;i++)
for(int j=1;j<=m3.m;j++)
for(int k=1;k<=m1.m;k++)
m3.z[i][j]+=m1.z[i][k]*m2.z[k][j];
return m3;
}
|
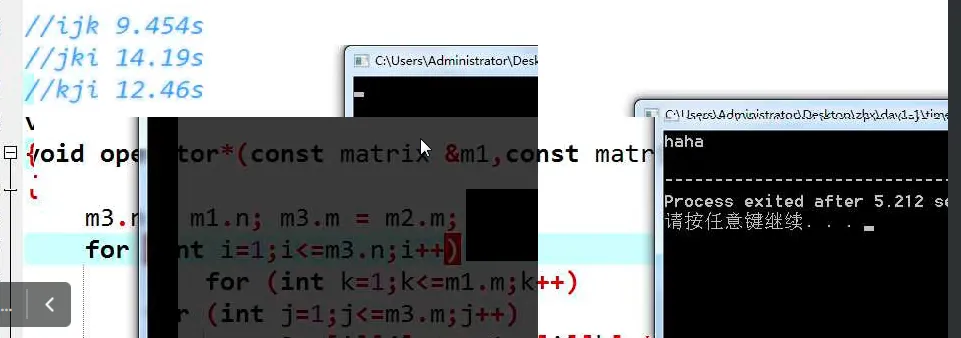
糟糕的复杂度:O(n3) 可处理百位(100~200)级别的矩阵乘法
小题题:P3390矩阵快速幂
memset
ijk
jki
kji
ikj
枚举顺序会影响时间复杂度?
把j放在最后是最快的
原因是缓存机制
缓存很小,但是很快
连续性越高,也就越快
尽可能让最后一维作为循环变量,以最大化利用缓存
j全部在第二维,最优
k只有一个在第二维,次优
i没有在第二维,最不优
相当于先处理答案矩阵的第一行,对第一行扫 k 遍便是结果,
- 处理答案矩阵的第一行
- 第一个矩阵的第一行的任何一个数都要被加一遍,第二个矩阵的第一列
来个小练习题:
求fn%p
暴力的写法
1
2
3
4
5
6
7
8
9
| cin>>n>>p;
int a=0,b=1;
for(int i=2;i<=n;i++)
{
int c=a+b;
if(c>=p) c-=p;
a=b;
b=c;
}
|
[fi−1fi−2]×[1110]=[fifi−1]
这样推n次就可以得到第n项
但是还不如直接算
怎么优化?
矩阵乘法也有结合律
这个东西是不是很眼熟
对于Bn可以进行一个[[数学#快速幂|快速幂]]
小题题P1962斐波那契数列
1
2
3
4
5
6
7
8
9
10
11
| matrix A,B;
A.n=1;A.m=2;
A.z[1][1]=1;
A.z[1][2]=0;
B.n=2;B.m=2;
B.z[1][1]=1;
B.z[1][2]=1;
B.z[2][1]=1;
B.z[2][2]=0;
matrix C=A*jzksm(B,n);
int ans=C.z[1][2]
|
复杂度:logn
虽然矩阵乘法是O(n3),但是B矩阵是个2×2的,23也就是8,可忽略
矩阵B是怎么来的呢?
小栗子
找到能够向后推一项的矩阵
[fi−1fi−2]×[3−210]=[fifi−1]
目的:向后推一项
再来一个栗子
刚才矩阵大小为2因为这一项的信息只与前两项有关
而这个却与前三项有关
[fi−1fi−2fi−3]×⎣⎡110001100⎦⎤=[fifi−1fi−2]
和前面几项有关,那么矩阵大小就是几
矩阵乘法有交换律吗?
no
补充:
矩阵快速幂加速递推的底层原理想了一会,觉得它跟正常的快速幂是一个原理,都是通过减少运算(递推)次数来减少运行时间。
又是一个小大栗子
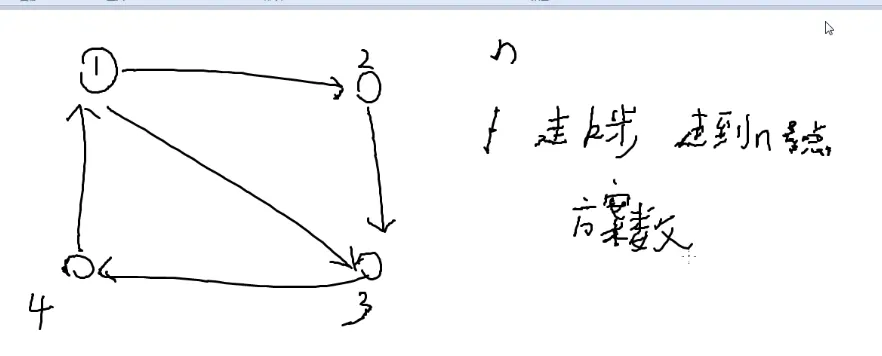
以下仅为简要写法,具体题解请见P4159 迷路
n≤100
k≤ 109
邻接矩阵存图
f[i][j]代表走了i步到达j的方案数
初始化:
f[0][1]=1
f[0][2∼n]=0
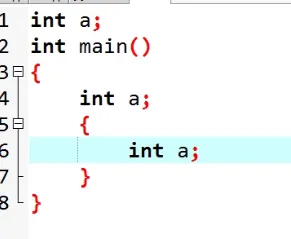
代码中可以出现相同变量名,前提是它们的作用域不同。
如何精确访问?
::a代表访问全局变量
正常的DP写法:
1
2
3
4
5
6
7
8
9
10
11
12
13
| cin>>n>>k;
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++)
cin>>z[i][j];
f[0][1]=1;
for(int a=1;a<=k;a++)
for(int b=1;b<=n;b++)
for(int c=1;c<=n;c++)
{
if(z[c][b]==1) f[a][b]+=f[a-1][c];
}
ans=f[k][n];
|
O(n3)复杂度肯定过不了
优化一下:
1
2
|
f[a][b]+=f[a-1][c]*z[c][b];
|
解释:c→b有边的时候,z[c][b]=1 就相当于转移
c→b没有边的时候,z[c][b]=0,就相当于加上0
那这样做有什么用呢? ——别急,往下看
升一下维度,中间始终为1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| cin>>n>>k;
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++)
cin>>z[i][j];
f[0][1]=1;
for(int a=1;a<=k;a++)
for(int d=1;d<=1;d++)
for(int b=1;b<=n;b++)
for(int c=1;c<=n;c++)
{
f[a][d][b]+=f[a-1][d][c]*z[c][b];
}
ans=f[k][1][n];
|
加维度、把判断变为相乘的目的就是为了把形式凑成矩阵乘法
f[i][j][k]DP意义实际上就是以j为起点,走了i步到达点k的方案数,只不过这里的起点是1
把f[a]当作变量
然后用下矩阵快速幂就搞定了
%% #Q: 但是 Z 这个数组时时刻刻在变化啊 %%
O(n3×logk)
小问题P4159
1≤ 边权 ≤9
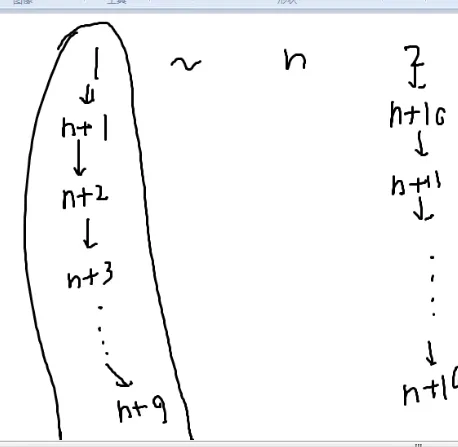
拆!
尽量少拆
最多延申九个点,加上原来的点,最多十个点
1
2
3
4
5
6
7
8
9
| cin>>n;
for(int i=1;i<=n;i++)
{
z[i][n+(i-1)*9+1]=1;
for(int j=1;j<9;j++)
{
z[n+(i-1)*9+j][n+(i-1)*9+j+1]=1;
}
}
|
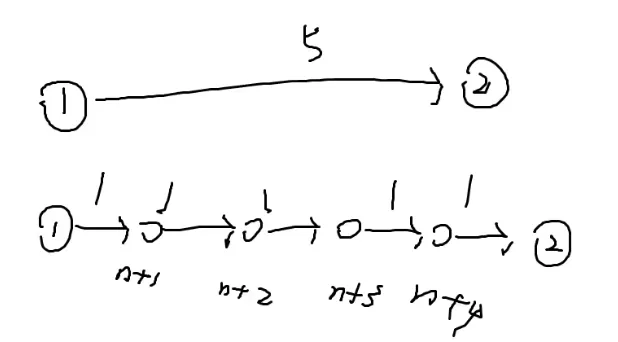
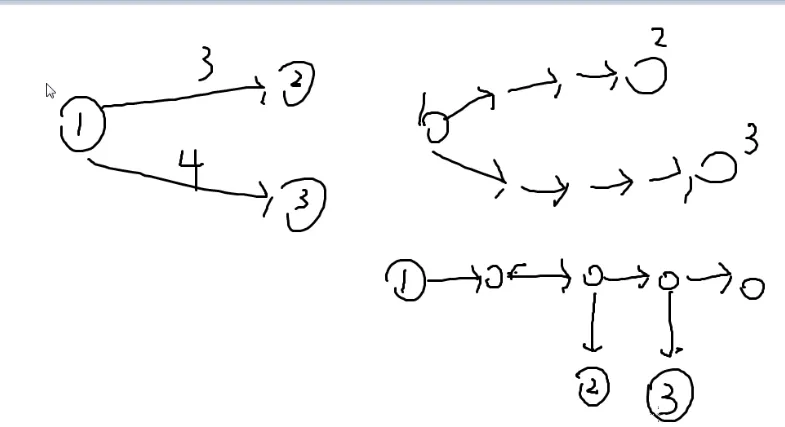
最终建出的图:
(距离为9的最后一个节点其实没有必要)
由图可知,这个矩阵长度和宽度是十倍的n
第一步是指1→n
第二步是指n+1→n+2→n+3…
假设n=5
加入对1→4有一条长度为6的边,那么就是:
假如是3→5长度为9
那么就是:
对长度为1特判一下,直接连边
对长度为0特判一下,直接continue
假如2→4长度为1
初等数论
质数
研究范围:正整数
素数:只有两个因子
除了质数就是 和数 和 1
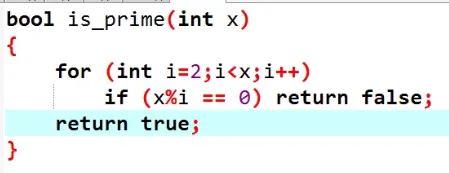
如何判断x是不是质数
有可能x是1或0
一个数的因子一定都是成对出现的
x=a⋅b
所以只需要枚举前根号个即可,大于 x 的质因子最后处理一下就可以了。
为什么没有两个大于 x 的质因子出现?
反证法:假如有,那么它们的乘积已经大于了 x,所以不存在。
典型错误:
这样会很man
因为每次都会重新调用一遍函数
修改:
x最大只能到x16
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| for(int a=2;a*a<=x;a++)
if(x%a==0)
{
cnt++;
prime[cnt]=a;
while(x%a==0)
{
num[cnt]++;
x/=a;
}
}
if(x!=1)
{
cnt++;
prime[cnt]=x;
num[cnt]=1
}
|
小练习:CF45G
哥德巴赫猜想:
始终不会超过三组
对于任何一个大于等于4的偶数,一定可以拆成两个质数之和
任何一个大于等于7的奇数,一定可以拆成三个质数之和
加和算出来是x
如果x是偶数,那么就是2组,
如果x是奇数,那么肯定小于3组
x本身是质数时答案为1组
剩下情况答案要么为2组,要么为3组
一个奇数可以看成一个奇数和一个偶数的和
若x−2是质数,那么就是2组,否则就可以拆成3组
逆元
逆元的引入
算完取模:
边算边取模:
理论上吧来说它也应该等于2
现在想计算a÷b%p
现在要把
如果能找到这个 c
c也就是 b1
那么c就是b的逆元
我们想用一个乘法来替代除法
费马小定理
当p是质数并且1≤a<p
那么一定有
ap−1modp≡1
ap−1≡1(modp)
这也就是费马小定理
两边同除a
ap−2≡a1(modp)
四分之一模p就是4p−2%p
a÷b%p=a×bp−2%p
那么b的p−2次方就可以用[[#快速幂|快速幂]]来求了
第一个条件是p是质数
第二个是a大于等于1小于p(a也可以比p大,因为一模p就肯定比p小了,只要它们互质就可以)
假如a>p,a与p互质,那么a%p还与p互质吗
依然互质,这不就是辗转相除法么
gcd(a,p)=1→gcd(p,a%p)=1
所以第二个条件是gcd(a,p)=1,也就是a和p互质
互质的概念:两个数的公因数只有1
那假如p不是质数怎么办
新定理:欧拉定理
欧拉定理&欧拉函数
使用条件:gcd(a,p)=1
aφ(p)≡1(modp)
φ(p)为欧拉函数
定义:一到p中有多少个数与p互质
φ(4)→ 1 3
φ(6)→ 1 5
和上面同理,两边同时除以a
aφ(p)−1≡a1(modp)
当p是质数的时候,φ(p)=p−1
a÷bmodp=a×b1modp=a×bφ(p)−1modp=a×bp−2modp
a和p不互质的时候,以上两种定理是不成立的,此时逆元不存在
这个时候我们认为这个用逆元是算不出来的
接下来问题来了,φ(n)怎么算呢
假设n=p1
假设p1是个质数,这时候φ(n)=p−1
假设n=p12?
p1的倍数都和p1都不互质
一共有p1个数和n不互质
那么φ(n)就是 p12−p1=p1×(p1−1)
那么假设为pk时,每p1个数就刚好有一个是p1的倍数
那么每p1个数就有p1−1个与n互质的
一共有n个数
所以φ(n)=pn1⋅(p1−1)
假设n=p1×p2
φ(n)=n−p1n−p2n+p1×p2n
解释一下,这个式子就是总共有n个数,每p1个数就会出现一个不与n互质的数(p1的倍数),每p2个数就会出现一个不与n互质的数(p2的倍数),减去不互质的数剩下的就是互质的数,我们发现每p1×p2个数就会出现一个不与n互质的数且为p1×p2的倍数(其实就是n),这个数被删了两次,所以要加回来一次
提取一个n出来
因式分解:
我们发现:
当n=p1k1⋅p2k2⋅p3k3⋯⋅ptkt时(p都是质数)(无论n为何值,一定能凑成几个质因数幂的乘积的形式——质因数分解)
📜 φ(n)=n⋅(1−p11)(1−p21)(1−p31)…(1−pt1)
根据容斥原理
现在要找的就是n的每个质因子,几次不用管
正确性的话,举几个例子就行了,毕竟,OI不需要证明
先除再乘防止范围炸掉
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| int get_phi(int n)
{
int phi = n;
for(int i=2;i*i<=n;i++)
if(n%i==0)
{
phi=phi/i*(i-1);
while(n%i==0)
{
n=n/i;
}
}
if(n!=1)
phi=phi/n*(n-1);
return phi;
}
|
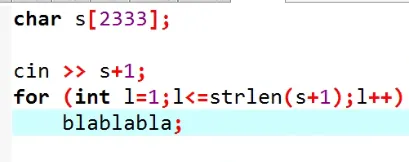
小问题:求n个数的逆元
阶乘的做法
最简单的做法:枚举一下
这么做的复杂度是O(nlogn)的,但是n比较大
先算出1到n每个数的阶乘算下来
只需要算n!的逆元
n的逆元也就是n1(模意义下)
每个数的阶乘分之1,从右往左推
再相乘,就求得逆元
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
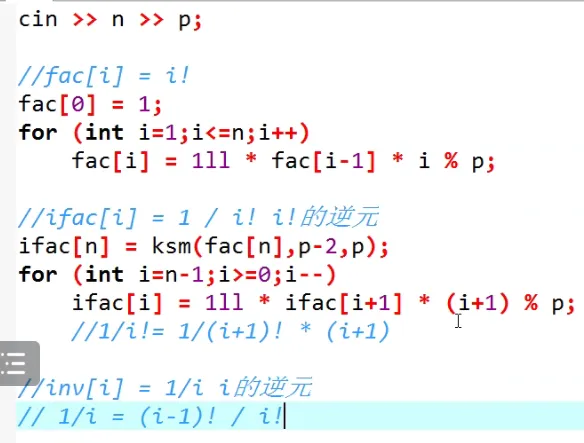
|
fac[0]=1;
for(int i=1;i<=n;i++)
{
fac[i]=1ll*fac[i-1]*i%p;
}
ifac[n]=ksm(fac[n],p-2,p);
for(int i=n-1;i>=0;i--)
{
ifac[i]=1ll*ifac[i+1]*(i+1)%p;
}
for(int i=1;i<=n;i++)
{
inv[i]=fac[i-1]*ifac[i]%p;
}
|
复杂度为O(n)
这是第一种方法
正推
首先1的逆元就是1
假设从左向右一个一个求
当我要求i这个数的时候
那么i−1个逆元都已经求好了
可以把它们都存下来
条件:质数p大于i
p%i一定小于i
设p=ki+r
因为i一定不是p的因子
1≤r≤i−1
现在想算i分之一
两边同除i
两边同除r
r是个小于i的数,因此它的逆元一定在之前求出来的
复杂度O(n)
1
2
3
4
5
6
7
| inv[1] = 1;
for(int i = 2; i <= maxn; ++i)
{
int k = p / i;
int r = p % i;
inv[i] = 1ll * k * (-inv[r] + p) % p;
}
|
由于是在模 p 意义下的运算,所以所有逆元都小于 p,所以加上 p 就可以防止负数。
模板题
Miller-Rabin
判断x是不是质数
复杂度为O(x)
假如x≤1018
假设n=37
n−1=36
36=9×22
当n为质数的时候
至少有一条成立
n不是质数的时候也可能满足。
假如一个都不满足,那么一定不是质数。
补充证明:
- Fermat 素性检验
由费马小定理可知,若 p 是素数:ap−1≡1(modp)
那么当这个等式成立的时候,p 就一定是素数?
不一定。
有部分合数无法被筛掉。
这个时候更换底数,可以增大它是素数的概率,但不管怎么换,仍然有合数无法被筛掉,所以我们需要引入另一个定理。
- 二次探测定理
对于素数 p 若 x2≡1(modp) 那么小于 p 的解只有两个,x1=1,x2=p−1。
证明:x2−1≡0(modp)→(x+1)(x−1)≡0(modp) ,
那么要么是零,要么是 p 的倍数。
所以小于 p 的解就是这两个。
两者结合一下:
先用 Fermat 检测得到 ap−1≡1(modp),这时候保证 p−1 是偶数,不然 p 是偶数就直接筛掉,那么就可以拆分为 (a2p−1)2≡1(modp) ,就可以用二次探测定理来判断了。
如果还符合,那就可以再进行同样的操作,直到里面的指数变为奇数。
也就是说,我们把 p−1=u×2t(u 是奇数),对 au,au×2,au×22 等数进行检验,它们的解要么全是一,要么出现 p - 1,注意,一开始没提取的时候是不能等于 p - 1 的,因为要满足费马小定理。
注意特判 a 是 p 的倍数的情况。
参考文章
#Q 为什么从出现解为 p - 1 后解就必须全是 1?
假如一个a只成立性质一,什么也说明不了,说明n有可能是质数。
换了一个a,两个性质仍然有一个成立,那么这个概率就会提高。
不断地往里带,假如一直成立的话,那么概率就会不断提高。
在i不断加一的过程中 ad在不断地在平方
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
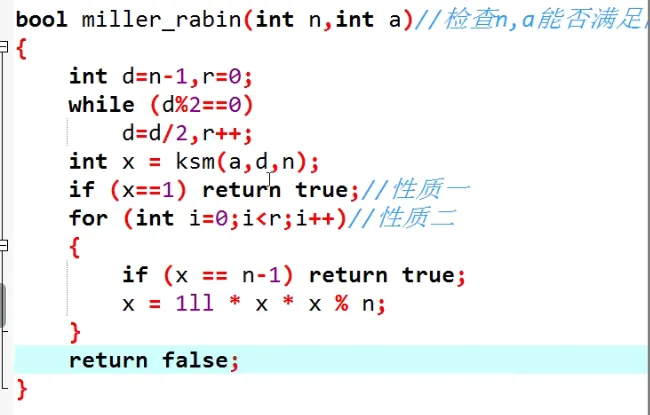
| bool mb(int n,int a)
{
int d=n-1,r=0;
while(d%2==0)
d=d/2,r++;
int x=ksm(a,d,n);
if(x==1) return true;
for(int i=0;i<r;i++)
{
if(x==n-1) return true;
x=1ll*x*x%n;
}
return false;
}
|
假如 ad 满足解为 1,那么不断把它平方,得到的解也必然为 1,因此对于第一个条件我们只需要检测 ad 是否满足即可。
枚举d和r以及快速幂复杂度都是logn的
一半概率对,一半概率错
20次检查后,仍然错误的概率就是2201
a∈1∼n−1
1
2
3
4
5
6
7
8
9
| bool is_prime(int n)
{
if(n<2) return false;
for(int i=1;i<=23;i++)
{
int a=rand()%(n-1)+1;
if(!mb(n,a)) return false;
}
}
|
第二种方法:定义一个质数表
在1018以内质数的概率更高(前人的智慧)
质数表可以自己去搜。
对于 232 以内的判素数,选 2, 7, 61 即可
对于 264 以内的判素数,选 2, 325, 9375, 28178, 450775, 9780504, 1795265022 即可。
对于考场上,选前 12 个质数作为底数即可,
2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37,适用于 278 以内的判断素数。
参考文章
EXGCD
gcd(a,b)=g
解决的问题 是为了解出ax+by=g
未知数个数比方程数多的时候,这个方程通常有无数解
我们只需要找到一组解
用辗转相除求x,y?
gcd(a,b)→gcd(b,a%b)
倒推
先讲讲最后一层
最终一定会得到:
gcd(a,0)=a
因为每次得到的一定是它们最大公因数的倍数
x⋅a+y⋅0=a
x=1,y=0(random)
假设已经找到了x′y′
怎么变成左边的式子?
只能推出y=x′,而不知道x,所以要往下化简
余数=被除数-除数乘商
a%b=a−⌊ba⌋×b
替换一下并整理:
和原来的比对一下:
ax+by=g
∴
x=y′
y=x′−y′⌊ba⌋
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| int exgcd(int a,int b,int &x,int &y)
{
if(b==0)
{
x=1;
y=0;
return a;
}
int xp,yp;
int g=exgcd(b,a%b,xp,yp);
x=yp;
y=xp-yp*(a/b);
return g;
}
|
这样就可以把x,y求出来
如果想要其它的解,那么只需要改变一下y的值就可以解出其它的解
性质
f(x)=ax+by
x,y都是任意整数
这个式子能表示出的最小正整数就是gcd(a,b)
证明:
x y 不管怎么变,相加都是g的倍数,
不能表示任意的数,
只能表示g的倍数,
所以最小的正整数就是它自己。
详细证明过程
比如:
这个方程没有整数解,
满足这个条件的前提下,
gcd(a,b)∣z
它才有整数解。
那么怎么解?
z是g的倍数
那么把exgcd解出后,两边同时乘k就是这个方程的解。
通项公式
P1082
假如不互质,那么这道题就无解,所以互质
ax≡1(modb)
ax一定等于yb+1
ax−by=1
和exgcd的区别?
没有区别
解出来解后给y加上负号就可以了
要求的时x
那么怎么保证正整数x最小呢?
随便找到一组解
把x变大n
y调小m
我们发现2n=3m
这样就可以把所有的解写出来
设解出一组解x=x0,y=y0
即an=bm
ba=nm
{x=x0+bky=y0−ak
这就是所有的解吗?
显然不是
假如a=4,b=6
要保证abk−abk=0又要保证ab的最大公因数不变,并且保证要整除,所以除去最大公因数最优。
{x=x0+gbky=y0−gak
我们发现x%gb=x0
这道题中g=1
x%b=x0
每个x都是b的倍数+n
那么最小的时候就是 x=xmodb 的时候。
假如方程两边同乘一个系数 k
方程变为:
akx+bky=kg
简写一下就是:
Ax+By=G
A=gG×a,a=Gg×A
B=gG×b,b=Gg×B
然后用 Exgcd 进行求解,
解得:
{x=x0y=y0
这是随便的一组解,并且不是 Ax+By=G 的解,而是 ax+by=g 的解,因为在计算 y′ 的时候乘的系数是 ⌊ba⌋ 。而 a、b 等比增加不会导致这个值改变,也不会导致 gcd(a,b) 发生改变,所以最后得到的解要乘上系数 gG=k 才是 Ax+By=G 的解。
也就是说方程的解为:
{x=kx0y=ky0
先看原来的方程,x 最小为多少?
x0modgb=x0modGB
那么在新方程里,x 最小为:
xmin=x0×gGmodGB×gG=x0×gGmodgB
练习题
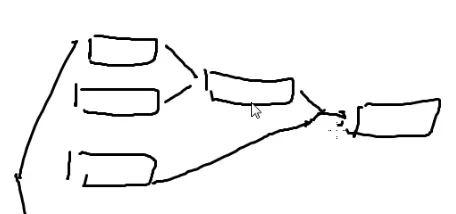
中国剩余定理
有一堆同余方程
我们现在要把它们合并为一个方程
这个方程就是我们要求的
首先想解x
x有几个解呢?
一共有n+1个未知数
n个方程
理论上会有无数组解
假设现在只有两个方程
x∈1,16,31…
x=1+15k
那么最后的解就是x%15=1
两个同余方程解出一个同余方程
那么n个呢?
可以不断拿两个同余方程合并,合并n−1次
最后必然也会只剩下一个同余方程
那么怎么把两个方程合并为一个方程呢?
大数翻倍法
ZHX:我很推荐你们用大数翻倍法,好写还不容易被卡,不像EXGCD难写还难调
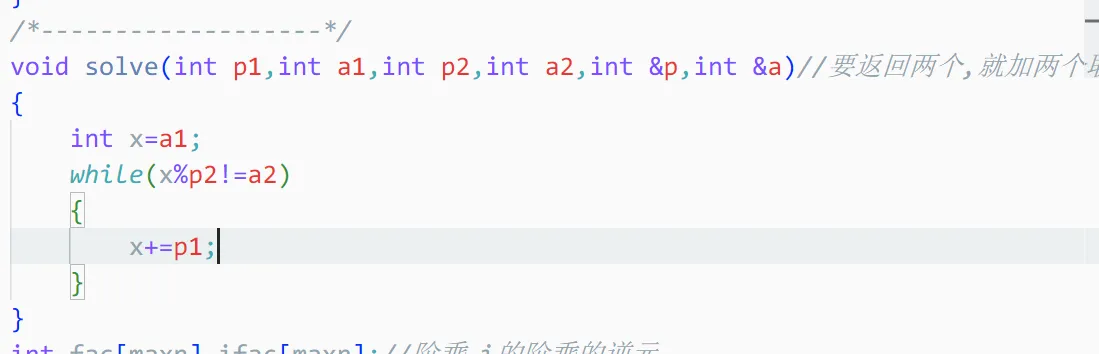
{x1%p1=a1x2%p2=a2
↓
x%p=a
考虑枚举,那么怎么优化呢?
可以强行让它满足第一个方程,再看它满不满足第二个方程
在a1的基础上不断加上p1
这样对吗?
假如这个方程无解,那么就会死循环
这时候%p2就是a1,相当于一个新的周期
超过最小公倍数就可以退出循环了
最小公倍数就是新方程中被模的数
x%15=7
假如让这个x模3的话
也就是kp+7%3,而p又是3的倍数,所以满足x%3=1,t 同理满足x%5=2
于是就是
x%l=a
极端情况下会运行p2次
时间复杂度是O(p2)次
大数翻倍法?
让大的数翻倍
让枚举次数变为更小的p1
时间时间复杂度为O(min(p1,p2))
最后解出来的p是所有p的lcm
复杂度
当p互质时候
要让所有p相乘小于1018
所以一般不太可能炸掉
想卡也不是很好卡
EXGCD法
{x1%p1=a1x2%p2=a2
↓
可以只看后半部分
↓
通过扩展欧几里得把k1、k2解出来
这里相当于+(−k2)
那么求出来以后k2=−k2即可
我按照k1×p1+k2×p2=a2−a1求得的x
我现在想知道k1×p1−k2×p2=a2−a1的解
那么令k2=−k2即可
筛法
埃式筛
给一个数n
尽量少的时间内把1→n所有的质数求出来
枚举a的所有倍数
a的倍数一定不是质数
把所有数的倍数都标记一遍
1
2
3
4
5
6
| for(int a=2;a<=n;a++)
for(int b=a+a;b<=n;n+=a)
not_prime[b]=true;
for(int a=2;a<=n;a++)
if(not_prime[a]==false)
prime[++cnt]=a;
|
复杂度:O(nlogn)
调和集数,约等于为logn
所以埃式筛的复杂度为nlogn
欧拉筛
前言
首先,4有必要枚举吗?
因为枚举2的标记的时候4的标记已经被标记了
1.只需要枚举质数的倍数就行
1
2
3
4
| for(int a=2;a<=n;a++)
if(not_prime[a]==flase)
for(int b=a+a;b<=n;n+=a)
not_prime[b]=true;
|
复杂度:nloglogn
证明一下为什么可以求倍数的过程中找质数
假设我枚举到了第22倍
那么我22之前的所有质数一定找完了
如果第22个没被标记,它一定不可能是一个和数
因为它只能被小于等于它的数标记
而不能被23、24标记
正文
现在一个数仍然有可能被筛多次
比如6,会被2和3都筛一次
比如30,会被2和3和5都筛一次
每个数都会被它的质因子筛一次
因为每个数质因子个数不是一个,因此大于n
我们要保证每个数只被筛一次
我们让它被最小的质因子筛掉
比如6只被2筛
55只被5筛
看代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| for(int i=2;i<=n;i++)
{
if(not_prime[i]==false)
{
cnt++;
prime[cnt]=i;
}
for(int j=1;j<=cnt;j++)
{
int x=prime[j]*i;
if(x>n)
{
break;
}
not_prime[x]=true;
}
}
|
还是nloglogn
加上一句话:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| #include <bits/stdc++.h>
using namespace std;
const int N = 1e5 + 7;
bool isprime[N];
int prime[N];
int n, cnt;
int main()
{
memset(isprime, true, sizeof(isprime));
isprime[1] = false;
for (int i = 2; i <= n; i++)
{
if (isprime[i]) prime[++cnt] = i;
for (int j = 1; j <= cnt && i * prime[j] <= n; j++)
{
isprime[i * prime[j]] = false;
if (i % prime[j] == 0) break;
}
}
}
|
首先找出了i=2
x=4
4就不是质数
第二轮,3也是质数
会把6和9也筛掉
筛掉8之后,4是第一个质数的倍数,会break
不会枚举到第三个质数
12也就没有筛掉
枚举到i=6时
此时i最小的质因子就是prime[j]
证明:
假如没有break
那么就会枚举第j+1个质数
x=prime[j+1]∗i
而i=k×prime[j]
x=prime[j+1]×k×prime[j]
由于质数表是往后递增的,因此最小质因子就是第一次被整除的prime[j]
小练习:P3383:线性筛素数
常用大小:
求积性函数
定义:
前提:a和b互质
完全积性函数:
不需要满足互质的条件
[[#欧拉定理|欧拉函数]]其实就是一个积性函数
q都是质数
φ()=?
证明过程:
我们发现φ(mn)的结果拆成两部分也就是n和m
O(n)求1→n的值
prime[j] 和 prime[i]
有可能不互质
假设它全互质,先按照函数定义求
那么不互质的怎么处理(也就是i和)
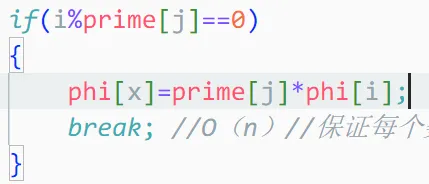
现在算φ(i⋅pj)
∵ i是pj的整数倍
∴ 质因子没有发生变化,也就是prime[j]的质因子和i的质因子都是q,只是次数不一样
后面那个东西就是φ(i)
所有数分为1+质数+和数
φ(1)=1
当n为质数,φ(n)=n−1
和数分为以上互质和不互质两种情况
BSGS(Baby Step Giant Step)
a,b,p
p是质数
求ax%p=b
也就是ax≡b(modp)
a,b,p≤109
写一下暴力
1
2
3
4
5
6
7
8
9
| void solve(int a,int b,int p)
{
int v=1;
for(int x=0;;x++)
{
if(v==b) return x;
v=1ll*v*a%p;
}
}
|
枚举到符合条件为止
假如无解,就会死循环
怎么判断无解?
初始状态就是1
再次出现若循环后依旧无解,那么就是无解
v的范围是0到p−1
[[#费马小定理|费马小定理]]:
一定会从1开始循环
ap−1%p=1
a0%p=1
循环长度为p−1
1
2
3
4
5
6
7
8
9
| void solve(int a,int b,int p)
{
int v=1;
for(int x=0;x<p-1;x++)
{
if(v==b) return x;
v=1ll*v*a%p;
}
}
|
a0=ap−1=1
怎么优化呢?
答案一定会在a0→p−1中出现
那我分个组
第零组是到从a0到as−1
s为每组的大小
把第零组的每个数都for一下
看下这s个数里有没有b
这样就知道答案的位置在哪里了
如果不在第零组,那么就去看第一组
还是for一遍
……
还是要枚举p次
那么第二次有没有更聪明的找法呢?
第零组乘以a的s次方就是第一组
如果要变回去的话那就是乘以a的−s次方
假如b在第一组出现了,那么第零组会出现下面这个东西
其实就是找第一组b⋅a−s
假如b在第i组出现了,那就要找第一组的a−is
把每一组都映射到第一组
这样就可以很方便地查询了
STL有一个东西叫set,可以存一堆数,查找一个数在这堆数中是否出现过
Set
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| begin();
end();
clear();
count();
empty();
equal_range();
erase()
find()
get_allocator()
insert()
lower_bound()
key_comp()
max_size()
rbegin()
rend()
size()
swap()
upper_bound()
value_comp()
|
看答案是否在第i行里面,第一行是第0行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| for(int i=0;i*s<=p;i++)
{
int c=1ll*b*ksm(ksm(a,i*s,p),p-2,p)%p;
if(se.count(c)!=0)
{
int v=ksm(a,i*s,p);
for(int j=i*s;;j++)
{
if(v==b) return j;
v=1ll*v*a%p;
}
}
}
|
由于越往下找答案肯定就越大,那么第一次找到一定就是最小值
注意这里i∗s可能会爆int,要开long long
第一层循环sp次
第二层循环枚举这一组中每一个数
最坏的情况就是O(s)
第二次循环只会执行一次,所以是加法原理
O(sp+s)
O(n+logn)=O(n)
我们只关心更大的
所以复杂度就是O(max(sp,s))
复杂度由较大值决定
所以sp=s的时候复杂度最优(基本不等式)
s=p
insert和count是log的
这也就是分块的思想
若要访问出现多少次,用map
组合数学
引入定义式
小栗子:
假如条件是互斥的(不能同时成立),那么就是加法
前面的选择和后面的选择是不同阶段的选择,前一阶段的条件对后续条件的选择没有影响
就乘起来
从三个人选出来两个人站成一列,有几种选法? ——排列
有六种选法
那假如从n个人中选m个人站成一列,考虑这m个人内部的顺序
P(n,m)=n⋅(n−1)⋅(n−2)⋅(n−3)⋅(n−4)⋅(n−5)…⋅(n−m+1)=(n−m)!n!
这样是考虑内部顺序的情况
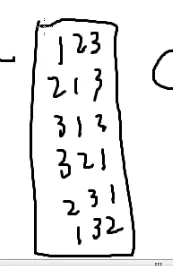
假如不考虑内部的顺序呢? ——组合
C(n,m)=n⋅(n−1)⋅(n−2)⋅(n−3)⋅(n−4)⋅(n−5)…(n−m+1)? ——显然不是
1,2和2,1是同一种方案,也就是m个人的内部随便怎么排都可以,都是一种方案
m个人内部随便排的方案数其实就是记录顺序地从m个人中选m个人,也就是:
m×(m−1)×(m−2)×(m−3)×(m−4)×…×1
想想第一个人选的时候有m种可能
那选第二个人的时候就有m−1种可能
以此类推
因为每次选择都是独立的,所以概率要相乘
也就是有m!种方案
三个人可以引伸为六种方案
也就是3!种方案
m个人内部可以有多少种顺序呢,答案是有m!种顺序,那就有m!种方案为同一种方案
C(n,m)=m!n⋅(n−1)⋅(n−2)⋅(n−3)⋅(n−4)⋅(n−5)…(n−m+1)=m!P(n,m)=m!(n−m)!n!
性质
C(n,0)=1
C(n,n)=1
P(n,n)=n!
1.C(n,m)=C(n,n-m)
保留m个和丢掉n−m个方案数相同
或者带进式子,会发现式子一样
2.🚩递推式
它们分别代表:
可以用背包的思路
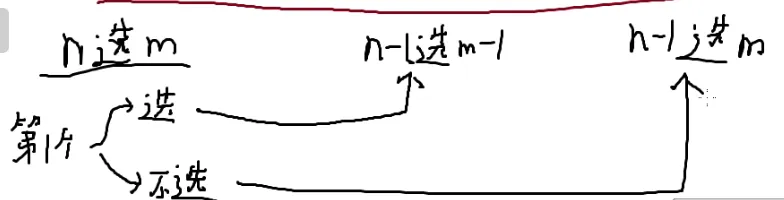
可以用第n个物品要选/不选
如果选的话,方案数就是选在n−1个数种选m−1个数的方案数,也就是C(n−1,m−1)
如果不选的话,方案数就是在在n−1个数中选m个数的方案数,也就是C(n−1,m)
因为选了以后就不能选了
所以是加法原理
这不就是杨辉三角嘛!
3.n个物品随便选
C(n,0)+C(n,1)+C(n,2)+C(n,3)+⋯+C(n,n)=2n
n个物品选0个物品的方案数
*n个物品选1个物品的方案数
*n个物品选2个物品的方案数
n个物品选3个物品的方案数
n个物品选4个物品的方案数
…
也就是从n个物品里任意选多少个的方案数
第一个物品要么选要么不选
一直到第n个物品,每个物品都是两种选择
那就是2n
4.奇方案=偶方案
加到/减到C(n,n)为止
移一下项
就是选偶数个东西的方案数等于选奇数个东西的方案数
可以画出当前这行的杨辉三角形
每一行的第一个都是1
偶数位置的和恰好把上一行每一个数加了起来
那假如是奇数?
也恰好把上一行所有位置加起来
选奇数的方案数=选偶数的方案数=2n−1
5.二项式定理
(x+y)0=1
(x+y)1=x+y
(x+y)2=x2+2xy+y2
(x+y)3=x3+3x2y+3xy2+y3
(x+y)4=x4+4x3y+x2y2+4xy3+y4
这不也是一个杨辉三角嘛
每行从左到右x次数逐渐减小,y的次数逐渐增加,系数就是杨辉三角数
- (x+y)n=C(n,0)xny0+C(n,1)xn−1y1+⋯+C(n,n)x0yn
但是这样写很麻烦
↓
求和运算符:Σ
- =i=0∑nC(n,i)xn−iyi
6.📌组合数的卷积(展开式)
C(n,m)=C(n−1,m−1)+C(n−1,m)=C(n−2,m−2)+C(n−2,m−1)+C(n−2,m−1)+C(n−2,m)=C(n−2,m−2)+2⋅C(n−2,m−1)+C(n−2,m)=C(n−3,m−3)+3C(n−3,m−2)+3C(n−3,m−1)+C(n−3,m)=……↓
C(n,m)↓=C(k,0)⋅C(n−k,m−k)+C(k,1)⋅C(n−k,m−k+1)+C(k,2)⋅C(n−k,m−k+2)+⋯+C(k,k)⋅C(n−k,m−k+k)=i=0∑kC(k,i)⋅C(n−k,m−i)
k表示展开k次,我们发现展开后多项式的系数就是杨辉三角数
C(n,m)=i=0∑kC(k,i)⋅C(n−k,m−k+i)=
亿些数学题
1.组合
一个数可以被选任意多次
m!nm?
每种方案重复的次数不一样
比如123(123,132,213,231,312,321),我有六种方式为一种方案
但假如是122(122,212,221),我只有3种方式为一种方案
正因为每个数可以重复并且重复的次数不一样,因此不可以同除一个数
那就是m个1,2,3,4,5,6?
也不对,每个2都是一个2
首先选m个数
a1a2a3a4a5a6...am
排个序,那么它就是递增的
大于等于1小于等于n
这个不等式解的个数
答案就是C(n,m)
所有的数从小于号变成了小于等于
现在要解的就是这个方程有多少组解
现在会解小于,考虑把小于等于转化为小于
那我再造m个变量
所以带进小于等于不等式
也就是从n+m−1个数中选m个
c的方案数就是C(n+m−1,m)
每一组b的解都对应着一组c的解
所以b的方案数也就是C(n+m−1,m)
相邻的不能选的情况呢?
亿点代码题(卢卡斯定理)
n,m,p
求C(n,m)%p
数据范围?
- n,m<=1018,P=1
输出0
- n,m≤1000 p无限制
递推式:
C(n,m)=(C(n−1,m−1)+C(n−1,m))%p
- n,m≤106,p是质数
因为p是质数了,所以可以用逆元
C(n,m)=m!×(n−m)!n!
除法可以用逆元搞定
1
2
3
4
| fac[0]=1;
for(int i=1;i<=1000000;i++)
fac[i]=1ll*fac[i-1]*i%p;
C(n,m)=1ll*fac[n]*ksm(fac[m],p-2,p)%p*ksm(fac[n-m],p-2,p)%p;
|
- n≤109 m<=1000 p无限制
大概是一个m2级别的才符合出题人的意图
一个题的突破口就是最奇怪的地方
因为p无限制,所以不一定是质数,可能逆元不存在
不用递推式可不可以?
m≤n
把能约的全部约掉
上面有m项,下面有m项
枚举上下两项
最后分母一定可以被约成1
答案就是把分子乘起来
复杂度:m2×logn
- n,m≤109,p≤100且为质数
卢卡斯定理
p为质数
把n,m转换为p进制的数
按位取C()再相乘
比如:
25=221
C(25,12)%3=C(2,1)⋅C(2,1)⋅C(1,0)%3
1
2
3
4
5
6
7
8
9
10
11
12
13
|
while(n)
{
x[0]++;
x[x[0]]=n%p;
n=n/p;
}
while(m)
{
y[0]++;
y[y[0]]=m%p;
m=m/p;
}
|
因为n大于m
所以正常情况下n转换为p进制的位数比m要大
所以按照n转化后的位数枚举就可以了
以最低位对齐,高位补零
时间复杂度?
不断除以p
那么就是logp的复杂度
那假如模的不是质数(这个数也不能是某个质数的若干次方)
那先对它先进行一个质因数分解
这不就是[[#中国剩余定理|中国剩余定理]]嘛
解同余方程就可以了
1.组合数拆解
n=1+1+1+1+1+1...+(n−k+1)
加上k−1个1
任何一个自然数都是组合数
2.比较组合数大小
数据范围:<=1000000
解法:
log
logx(ab)=loga+logb
logx(ba)=loga−logb
log可以反映大小关系
logC(n1,m1) logC(n2,m2)
假如C1<C2那么一定有logC1<logC2,反之亦然
logC(n,m)logn!=logm!×(n−m)!n!=logn!−logm!−log(n−m)!↓=log1+log2+log3+…logn
这样就可以求出logC(n,m)的值就可以进行比较大小了
精度误差?
这个是在小数点后很多位产生的误差
因此可以忽略不计
3.找最大组合数
P4370
对某个数取模,不需要考虑和是什么
最大的数一定在最下面的最中间
最下面那不就是第n行嘛,也就是第n行的最中间n/2
要求组合数,要么就是带入公式,但是这里模数不一定为质数,所以只能用递推式
第二大的一定在它的周围
下一个最大的在第二大和第一大的组合数周围
怎么比较大小呢?
上一道题就说了
那就可以用BFS做了
但k比较大
可以加堆优化
4.组合数问题
P3746
一开始的f(n,r),往下化简
^1121
展开k次
按照[[#6.📌组合数的卷积(展开式)|展开式]]
C(n,m)=i=0∑kC(k,i)⋅C(n−k,m−i)
C(nk,ik+r)=j=0∑k
出现了很多Σ
这个叫做求和变形
常用的技巧:
- 增加枚举量
- 交换枚举顺序
- 分离无关变量
什么叫做分离无关变量呢?
这个式子里变得是i和j
i变了第二个式子就会变,但第一个式子不会变
那就可以把第一个式子提出去
- [[#7.|换元法]]
求完和再统一去乘
这还是两层循环
想想题目开始时设的f,现在已经化简成了这样
i,j控制的是圈起来的部分,这个地方就可以把∞消掉
![[#^1121]]
那就能化为
老规矩,加一维,凑成矩阵乘法
第一行第r列
令
f0就是n=0时的值,往公式里带就可以了
抽屉原理
一般来讲小的为抽屉
所以c是抽屉,n是东西
陷阱:选任意多个数,但不保证连续,但其实连续更好做
前缀和:
n个数的前缀和一定有n+1个
n+1>n≥c
按照模c以后的数分组
那就是 0→c−1
一共有c个抽屉
n+1个前缀和,按照模数分组
那么一定有一个抽屉有两个前缀和,前缀和肯定是几个数相加
这两个数模c是同余的
那它们的差一定就是c的倍数
那前缀和之差肯定就是某段区间的和了
1.正方形覆盖
假如L=100能盖住
那L=150一定也可以盖住
假如L=100不能盖住
那么L=50一定也不能盖住
考虑二分答案
那么现在问题是已知L,能不能覆盖所有点
这题有个很特殊的数字3
3和抽屉原理有什么关系
可以把平面上所有点分为四块
最靠上/下/左/右的点为边界
至少有一个正方形会盖住两个点
要么左上角/右上角/左下角/右下角
枚举一下就可以了
假如放在左下角
盖住一个区块后
剩下的点还可以构造一个四边形
现在还剩两个正方形
至少有一个正方形至少盖住两个边界点
再枚举一次(枚举的是盖住哪个角,而不是盖住几个点,盖住几个点都不重要,我们想知道的只是最后能不能全都盖住)
再把没有被盖住的点拿出来,看看最后一个正方形能不能盖住剩下的点就可以了
这样就可以判断能不能用长度为L的正方形能不能盖住了
每次盖住就要重新求一遍边界点,为O(n)级别
然后枚举十六种情况
也就是O(16n)
为什么放角上是最优的?
因为再往外移就会浪费面积
没有盖住任何点
我倒不如往里移让它盖住更多的点
容斥原理
加上所有一个式子,减去所有两个式子,加上所有三个式子,减去所有四个式子
n对夫妻问题
2n个人坐成一圈
每对夫妻不能坐在相邻的位置
旋转后相同的算一种
假如不要求不相邻,让他们作为一排
有两种解释:
第一种:
一排的方案数是n!
坐成一圈呢?
n个人坐成一圈的人可以转出n种方案
所以就是n!÷n
=(n−1)!
第二种:
假如第一个人定死了,剩下n−1个人坐n−1个位置,还是(n−1)!
回到题目本身的要求上:每对夫妻都不能相邻
原来有2n个人
随便坐的方案数:(2n−1)!
但这里面包含不合法的方案数
那就把它减去就可以了
我可以让一对夫妻强制坐在一起,那么这种一定不合法
n对中选出一对夫妻强制相邻:C(n,1)⋅(2n−2)!
可以把强制相邻看作让把一个人强制绑定到另一个人身上,也就是让这(2n−2)个人围成一圈做全排列
虽然强制相邻,但男左女右,男右女左也是两种方案
所以还要再乘以2:C(n,1)⋅(2n−2)!⋅2
这就是答案吗?
但有没有可能把一种不合法的方案删了多次呢?
如果一个方案里,既有第一对相邻,也有第二对相邻,那么这个方案会被减掉两次
发现被多减了
(2n−1)!−C(n,1)⋅(2n−2)!⋅2+C(n,2)⋅(2n−3)!⋅x2
我们又发现多加上了三对夫妻相邻的方案数
那么就不断加加减减下去,最后写成Σ的形式
有i对夫妻强制相邻
i=0∑nC(n,i)⋅(2n−i−1)!⋅2i
那么加减呢?
观察上面的式子
发现规律:奇数减,偶数加
为了使奇数减,偶数加,那么就要再做一点修改:
i=0∑nC(n,i)⋅(2n−i−1)!⋅2i⋅(−1)i
把n对不坐在一起的问题转换为只限制一对,两对,三对……
x的y次方
HDU2204
P9118
y最大的多少?
要保证2y<1018,这是x最小的(1的任意次方等于它本身)
那么y<64
1−100有多少个数能用x2表示?
这个答案显然是100个
那么1→N能表示xy的数一共有yN个
那么答案是这个吗?
比如64,y=2的时候会被8算一次
y=3的时候会被4算一次
y=6的时候会被2算一次
要把它减掉
−6N
决定y次是加还是减呢?
可以用莫比乌斯函数
先暴力
当算到x2的时候x4,6,8…都会被算
也就是a的倍数都要+1;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| cin>>n;
for(int a=2;a<=64;a++)
{
num[a]=0;
}
for(int a=2;a<=64;a++)
{
long long v=pow(n,1.0/a)-1;
int d=1-num[a];
ans+=v*d;
for(int b=a;b<=64;b+=a)
{
num[b]+=d;
}
}
ans++;
|
pow(n,1.0/a)=an
∵2log2n=n
∴原式=na1
=an
log和exp在cpp里都是以e为底的
以什么为底都一样
exp(x)就是ex
线性基
矩阵
矩阵乘法和前缀和很像
高斯消元
解方程
{x1+x2=22x1+3x2=5
{x1=1x2=1
假如稍作变化呢?
n个未知数
要解决n元一次方程,怎么解?
要把未知数消去
x1就消失了
x1也消失了
(i)−(1)⋅ai1a11
可以用第i个方程-第一个方程乘以a11分之ai1就可以把所有的x1消掉
只有n−1个方程,n−1个未知数了
不断减去第一行就可以消掉x1,剩下的方程不断减去第二行就可以消去x2,…
不断这样做下去就可以做成一个方程,一个未知数
解出来后一步一步往回带,也可以变成只剩一个未知数
写一下代码
i=1
i=2
会变成一个三角形
所以消元后
最后的方程会在最后一行
一般也就100→200
题目保证有唯一解
假如a[i][i]=0?
任何一个a[i][i]=0
这样拿第一个方程的x1消去其它方程的x1,没有办法消元,因为第一个方程压根就没有x1
所以我要用第i个方程消去xi要先保证有xi
可以交换
代码:
1
2
3
4
5
6
7
8
| cin>>n;
for(int i=1;i<=n;i++)
{
for(int j=1;j<=n;j++)
cin>>a[i][j];
cin>>a[i][n+1];
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| void gauss()
{
for(int i=1;i<=n;i++)
{
for(int j=i;j<=n;j++)
{
if(a[j][i]!=0)
{
for(int k=1;k<=n+1;k++)
swap(a[i][k],a[j][k]);
break;
}
}
for(int j=i+1;j<=n;j++)
{
double ratio=a[j][i]/a[i][i];
for(int k=1;k<=n+1;k++)
{
a[j][k]-=a[i][k]*ratio;
}
}
}
for(int i=n;i>=1;i--)
{
for(int j=i+1;j<=n;j++)
{
a[i][n+1]-=a[i][j]*x[j];
}
x[i]=a[i][n+1]/a[i][i];
}
}
|
int的话写不等于0就可以了
但是这里面所有的方程都是double类型的,不可以用!=0来判断
应该这样写
1
2
3
| if(fabs(a[j][i])> 1e-8)
......
double ratio=a[j][i]/a[i][i];
|
但实际上这种高斯消元很容易被卡
主元消元法
精度问题
换哪个呢?
一个会除以0.1
一个会除以10
数学意义上无所谓
但第二个会更好
除以10会更好
假如精度误差到了0.01的级别
0.1会使它波动到0.09→0.1
第二个波动范围更小
因为误差会随着数一起变
数变大误差也就会变大,数变小误差也会变小
这里选的a[i][i]应该越大越好
主元消元法:
找到系数最大的那个作为被除数使最优的
假如系数和解都是整数呢?
可以存分子分母
也可以:
举个栗子:
假如还是那么写,要乘1.5倍
那就可以把它们都变成各自的最小公倍数
这样就可以避免出现小数
但是不断求LCM这样系数可能会越来越大
所以要开long long
要是long long还不行就得去用double的方法了
1
2
3
4
5
6
7
8
9
| double a[][];
cin>>n;
for(int i=1;i<=n;i++)
{
for(int j=1;j<=n;j++)
cin>>a[i][j];
cin>>a[i][n+1];
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| void gauss()
{
for(int i=1;i<=n;i++)
{
for(int j=i;j<=n;j++)
{
if(a[j][i]!=0)
{
for(int k=1;k<=n+1;k++)
swap(a[i][k],a[j][k]);
break;
}
}
for(int j=i+1;j<=n;j++)
{
if(a[j][i]==0) comtinue;
int l=a[i][i]/gcd(abs(a[i][i]),abs(a[j][i]))*a[j][i];
int retioi=l/a[i][i];
int retioj=l/a[j][i];
for(int k=1;k<=n+1;k++)
{
a[j][k]=a[j][k]*retioj-a[i][k]*ratioi;
}
}
}
for(int i=n;i>=1;i--)
{
for(int j=i+1;j<=n;j++)
{
a[i][n+1]-=a[i][j]*x[j];
}
x[i]=a[i][n+1]/a[i][i];
}
}
|
解方程
可以怎么用高斯消元呢?
输入一个数,输出一个数,一般可以打表
打表打不下的时候可以找规律
假设答案是关于n的一次方程
可以得到若干个方程
假如规律不对
那就把它当成2次的式子
在把n=4带进去
若还不满足
再升幂
次数比较低的时候可以手解
那么就可以枚举这个规律是几次的
那就把它带到下一项去验证
这样就可以找到规律
条件:一定是n的多少次方
矩阵求逆
矩阵I叫做单位矩阵
假如A×B=I
矩阵B是矩阵A的逆矩阵
矩阵A是矩阵B的逆矩阵
怎么求逆矩阵呢?
i=j的时候=1
i!=j的时候=0
这样才能保证得到一个单位矩阵
n2个未知数,n2个方程,这样就可以把逆矩阵求出来了
那么这个的复杂度就会是n23
也就是n6
有亿点大
怎么优化呢?
用一个小小的小技巧
对角线有两个是0,它们所在的小矩阵,1变成了另一个对角线
这个矩阵可以交换第二行和第三行
可以动手算一下
那假如是这个:
对角线为1
其实就是把第一行的两倍加到第二行上
就是把某一行的若干倍加到某一行上去
高斯消元的核心操作:交换某两行,把一行的若干倍加到某一行上去
高斯消元每一步相当于做矩阵乘法
一开始有个矩阵A
A×B=I
用高斯消元不断消A,把它消成I
正着消除一遍,再倒着消除一遍
就可以把矩阵化为I
其实就是乘了个B
把消元的过程中把同样的操作在矩阵I同样做一遍
就可以把A×B→I,I×B→B
就相当于对一个n×2n的矩阵消元
左边是A,右边是I
概率和期望
概率
概率:一件事发生的可能性
什么是事件呢?
比如扔骰子🎲,可能扔出1,2,3,4,5,6
这六个数叫做样本空间
每一个值叫做一个样本点
事件:几个样本点的集合
A={1}→61
A={1,2,3}→21
- 交集
- A∩B=A⋅B
- A∪B=A+B
- A−A⋅B=A−B
那A−B是什么呢?
A里面在B种出现过的扔掉
就是A减去A和B的交集
除法呢?
除以一个矩阵=乘上它的逆矩阵
每个样本点的概率不一定是相等的
A1,2,3=A1+A2+A3
性质
假如有个事件概率为P(A)
任何一个事件的概率都是0→1的一个实数
所有样本点的概率之和为1
P(A)=0,叫做不可能事件
P(A)=1,叫做必然事件
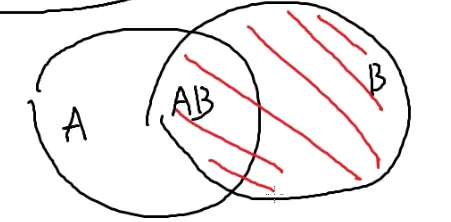
P(A∣B) 条件概率:B发生的情况下,A发生的概率
看B事件的发生对A产生了何种影响
B事件改变了它的样本空间
P(A∣B)=31
再换个栗子
P(A∣B)=A1+A2+A3=31+0+31=32
P(A∣B)=P(B)P(AB)=2131=32
一共六个样本点
独立事件
A是否发生和B是否发生没有关系
P(A)×P(B)=P(AB)
P(A∣B)×P(B)=P(AB)
P(A)=P(A∣B)
A发生的概率=B事件发生的情况下A发生的概率
因此B时间的发生对A时间的发生没有影响
这个时候这两个事件就是独立的
比如扔两枚骰子🎲/生两个孩子👶
期望
扔一枚骰子🎲
每种情况发生的概率是61
扔出来的数的期望是什么?
用每一种情况的这个数去乘以这个情况的概率
第一种情况就是1×61
第二种情况就是2×61
…
第六种情况就是6×61
把这六个式子加起来就是数的期望
也就是扔出来数的平均值
每个事件有一个概率,每个事件有一个权值
权值x概率之和就是期望
扔出来数平方的平均值
假如十个测试点,输出Y/N
假如我写了个cout<<Y<<endl;
这个期望是50分
每个测试点有一半概率是Y一半概率是N,一个测试点是十分
假如概率不一样呢?
还是一样算
性质
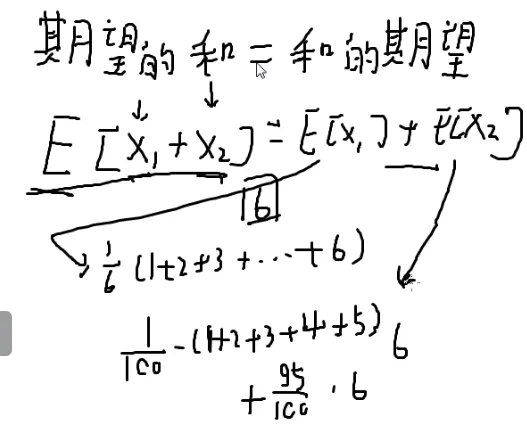
期望的和=和的期望
一枚骰子灌铅,一枚骰子不灌铅
E代表期望
E[x1+x2]
两枚骰子有三十六种情况
得算一遍三十六种
再来几枚骰子呢?
这东西就没法算了
期望的和=和的期望
E[x1+x2]=E[x1]+E[x2]
这个式子永远都可以用
即使有关系也可以用
假如要算E[x1+x12]
就是=E[x1]+E[x12]
与它们独立不独立没有影响
Problem
1.
P(Black∣Red)
比如两面都是黑色的就被排除了
另一面的概率是黑色和红色概率真的一样吗?
选牌的时候,放哪面呢?
有六种情况
第一张牌:红|红
第二张牌:红|黑
第三张牌:黑|黑
条件概率P(下黑|上红)=P(下黑上红)÷P(上红)
分子是六分之一
分母是二分之一
最终的概率就是三分之一
因为第一张牌两面都是红色,拿它摆上来正面是红的概率要比一红一黑这张牌摆上来正面是红的概率要高
2.
公平:每个人中奖的概率是一样的
第一个人中奖的概率是n分之一
第二个人中奖的概率:第一个人没中奖的概率乘以第二个人中奖的概率
第三个人中奖的概率:第一个人第二个人没中奖的概率乘以第三个人中奖的概率
3.
条件概率
P(男人|色盲)=P(男人×色盲)除以P(色盲)
=51%x2%/51%x2%+49x0.25%
4.
(1)取了2n−m+1次
哪个空了?
虽然取右边的概率比左边大
也有可能左边(1−p)先被取完
- 右边口袋空了
- 右边取
- 左边口袋空了
- 右边取了n−m次
- 左边取了n+1(又取了一次才发现空了)
- 第一次取到左边和第二次取左边的概率相同
- (1−p)(n+1)p(n−m)把左边取光的概率是这个东西吗?
- (1−p)(n+1)p(n−m)这个式子的意思实际上是顺序取的概率,完全可以交替取,是可以换顺序的,左于左之间是不计顺序的,一种情况的概率是这么多,那么这么多情况叠加起来就是要乘以情况数,因为不记顺序,所以是组合而不是排列(不清楚的可以回去看[[#组合数学|排列和组合的区别]]);乘上C(2n-m,n)和乘上C(2n-m,n-m)其实是一回事,是相同的这么多次情况,所以没必要乘两遍
- 最后一次一定是左边,最后发现的时候是左边,前面还差(2n−m)次可以任意(
n次左,(n-m)次右) - (1−p)(n+1)p(n−m)⋅C(2n−m,n),
- 两问,每问两种情况,一共有四种情况,这只是其中一种情况,记得乘上组合的方案数
(2)取了2n−m次
5.
换不换都是一样的
前置:三门问题
现在有三扇门,一扇门后面是车,另外两扇门后面是羊🐏,你想要车
你选了一个门,主持人打开另外两扇门中的一个
这扇门后面是羊🐏
换了是三分之二
不换是三分之一
和本题有什么区别呢?
这个问题出在小泽和主持人上
并不是同一个角色
主持人是知道哪扇门
主持人没有任何概率会打开车的那扇门
我选三个门的概率是一样的
枚举一下:
- 我选了一号门
不换二号门
不换二号门
- 选了二号门 主持人打开三号门
换一号门
- 选了三号门,主持人打开二号门
换一号门
本题
一共六种情况
这是一个条件概率
小泽死的情况下
我拿到的是好药
P(好,挂)除以P(挂)
小泽挂掉,分母是六分之四
小葱活下来,小泽挂掉,所以分母是六分之二
概率问题中,知道的信息量不一样就会导致事件的概率不一样
6.
哪边挂掉的概率小一些呢?
(1)
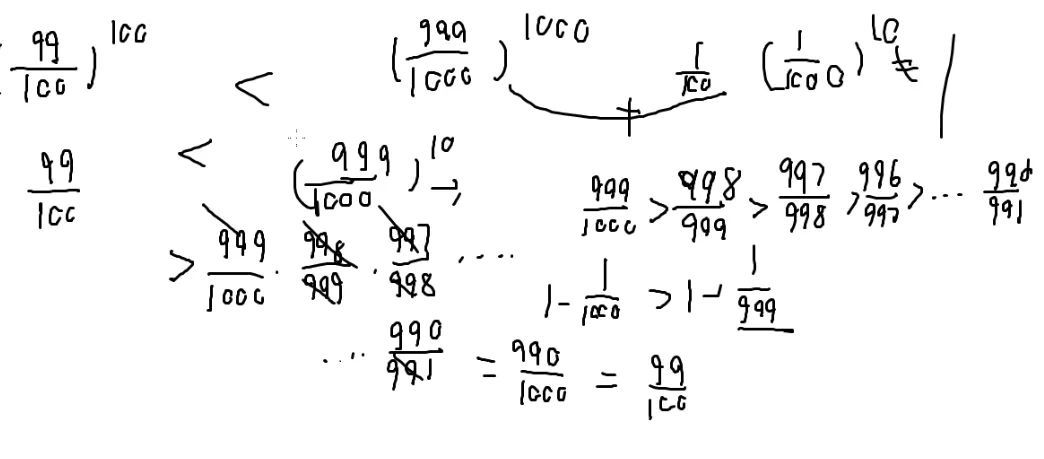
第一条路不挂掉的概率=99100%
(2)
第二条路每个石头都不挂掉的概率是99.91000%
这两个谁大?
∵1000999>999998>998997…>991990
∴100099910>1000999⋅999998⋅998997…⋅991990=1000990=10099
7.
经过原点的概率?
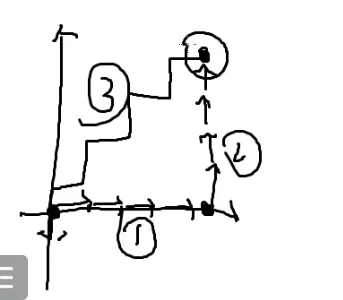
首先有三个阶段
第二阶段的末尾和第三个阶段的起点很关键
而第一个阶段和第二阶段极端情况下可以走无穷步
也就是第一象限所有的点都有可能
也就是x=0∑∞y=0∑∞
第一阶段走到(x,0),走x步,x次反面(1−p),概率为(1−p)x×p
停下来的概率?
也就是抛一次正面的概率p
第二阶段走到(x,y),走y步,y次反面,概率为(1−p)y×p
停下来的概率是p
走到(x,y)了,要走第三阶段,走回原点
q:向左走
(1−q):向下走
要抛x+y次才能回到原点
恰好抛x次正面,y次反面才可以恰好回到原点
qx*(1−q)y
但是还有组合顺序(不计内部顺序,详见[[#组合数学|排列组合]]和[[#4.|火柴]]):qx*(1−q)y×C(x+y,x)
在x+y个位置找x:C(x+y,x)
化简呢?
[[#4.组合数问题|求和变形]]:
- 变化量有两个:x和y,但是x+y随着x,y变化:换元法
令t=x+y
y=t−x
枚举到t
那么怎么分离无关变量呢?
p2
右边这个东西是不是很眼熟?
[[#5.二项式定理|二项式定理]]
(q+1−q)t
这是一个等比数列求和
设它为x
两式一减
a就是(1−p)
一个零点几的数的无穷次方=0
那答案就是p
全过程:
8.
三个矩阵都是n×n的
看来不能直接乘,n3会TLE
可以不算整个矩阵,可以随机几个位置
如果有一个位置不相等,那么一定不同
但这样可以吗?
假如只有一个错的
随机到那一个错的概率是一百万分之一
这个方法过不了
有没有什么正确率高一点的随机方法
现在的问题是矩阵A和B是算不出来的
造一个矩阵D
矩阵D大小为n×1
矩阵乘法有结合律
可以先算BD
反过来对吗?
假如D全是0
想想[[数学#Miller-Rabin|miller]]
随机一个D
假如通过不了测试
那就不是;如果是,就再随机一个D
拿每个矩阵去算一下ABD和CD
每相等一次,相等的概率就会足够高
加权求和并且错到一起的概率是相当低的
也就是这个的正确率是相当高的
n越大,加权求和的随机率越高,正确率越高



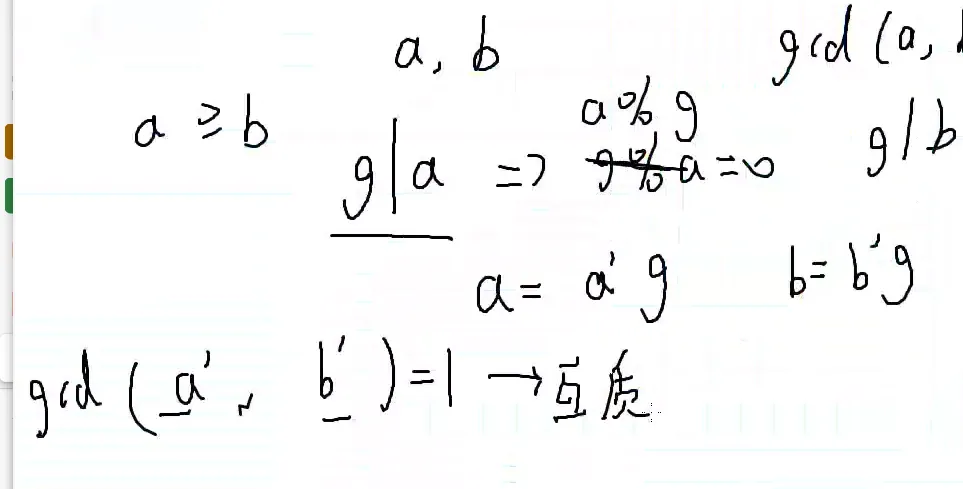
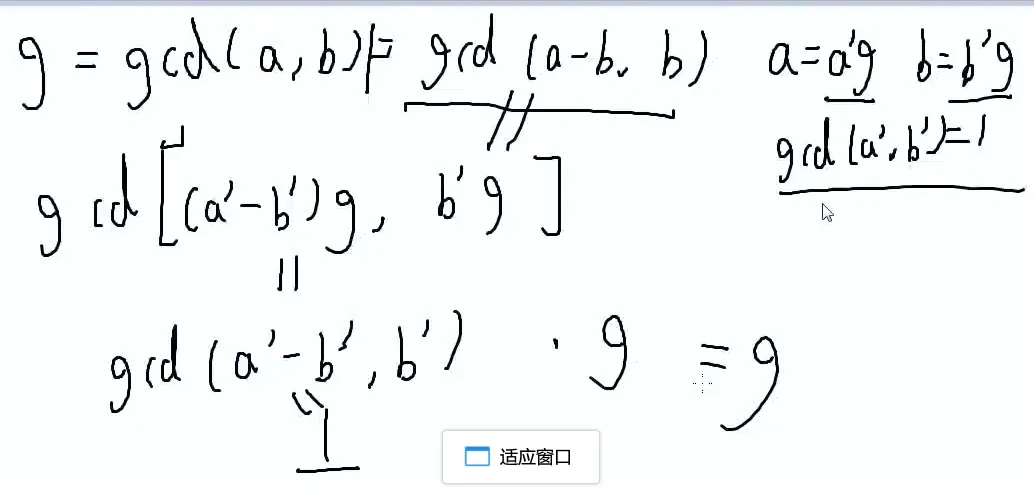
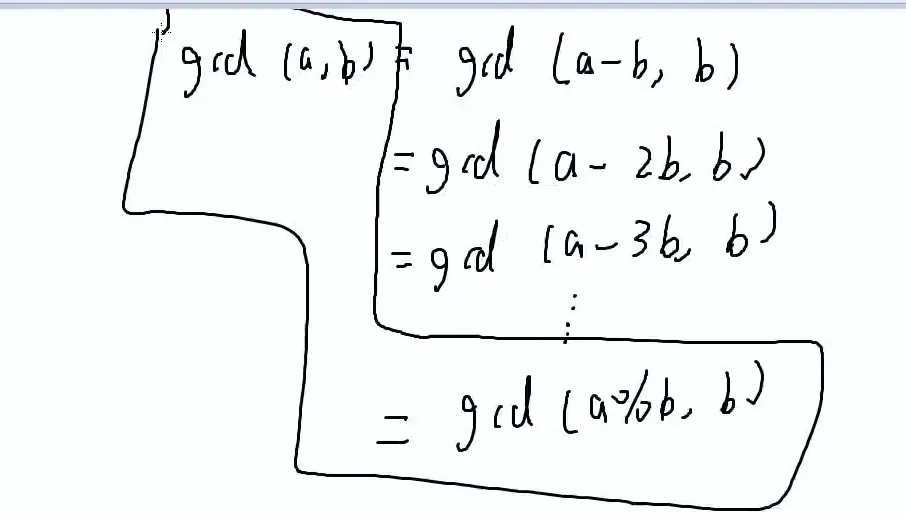
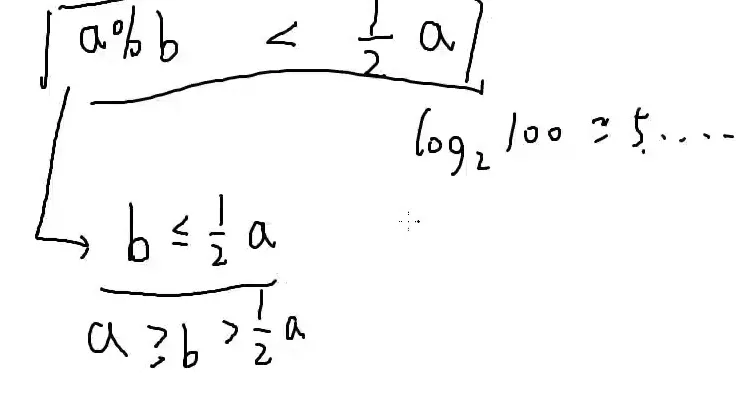
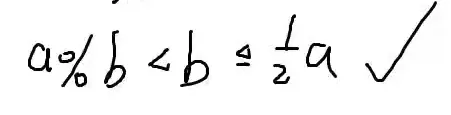
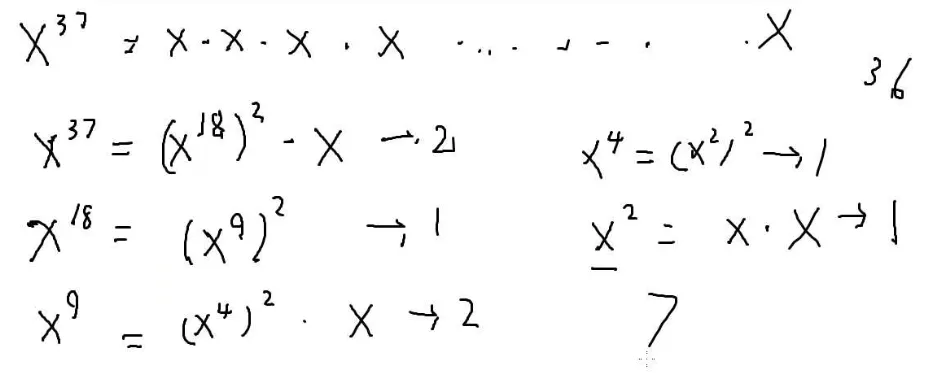
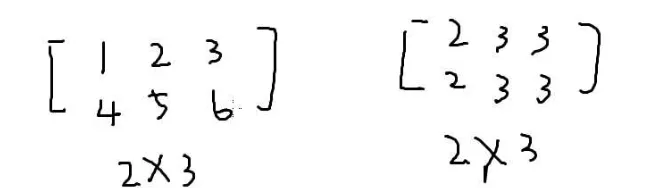
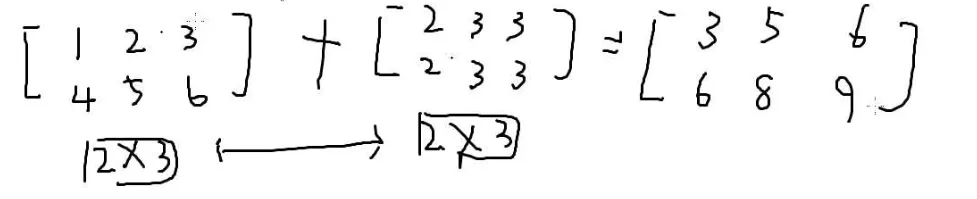
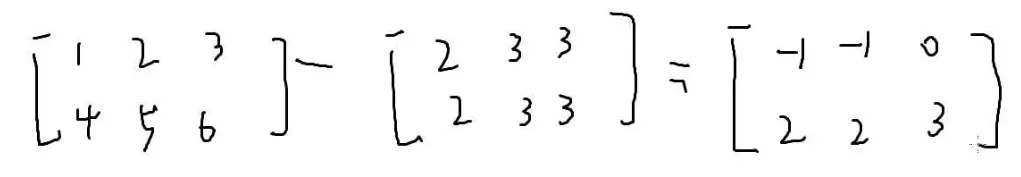
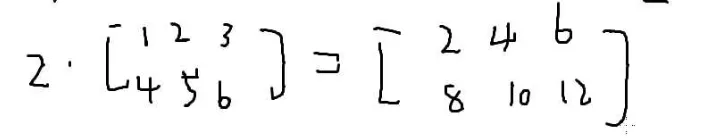
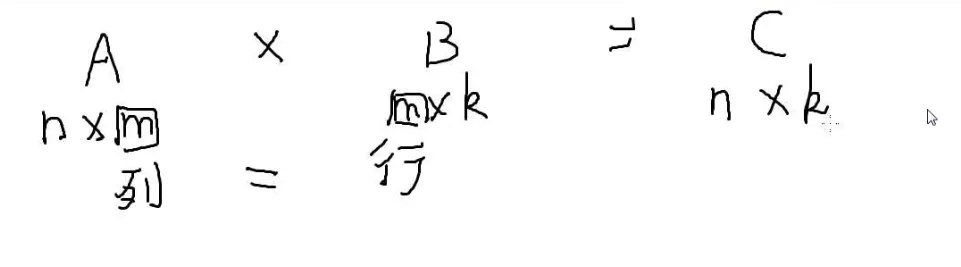


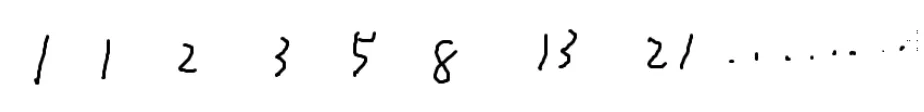
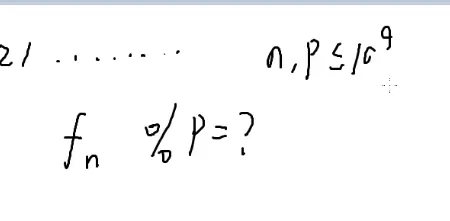
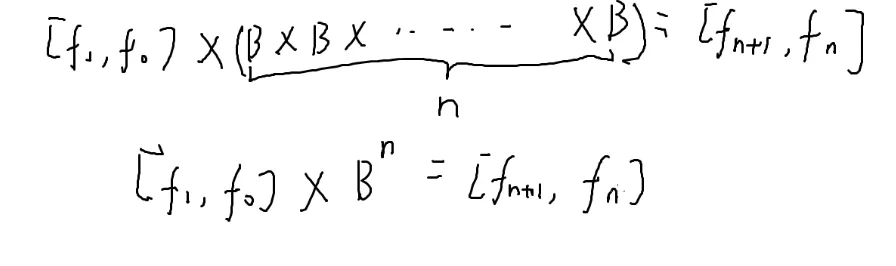
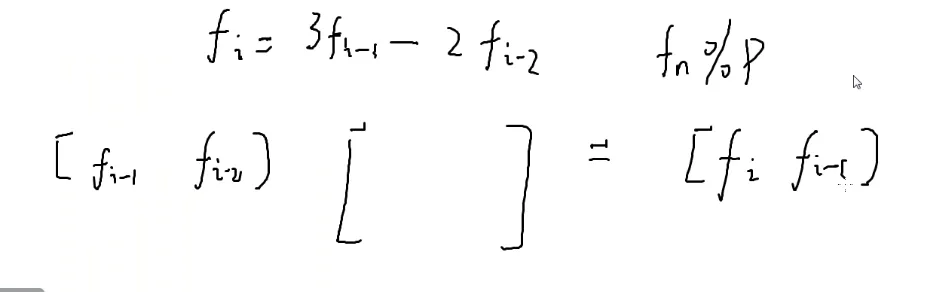
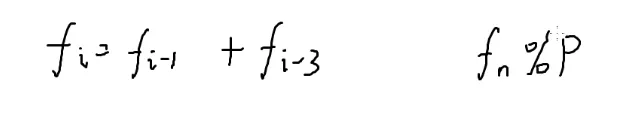
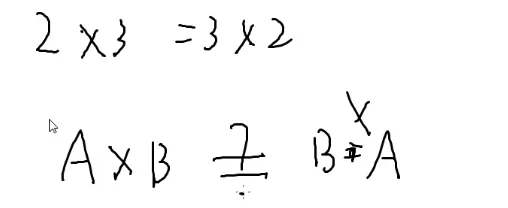
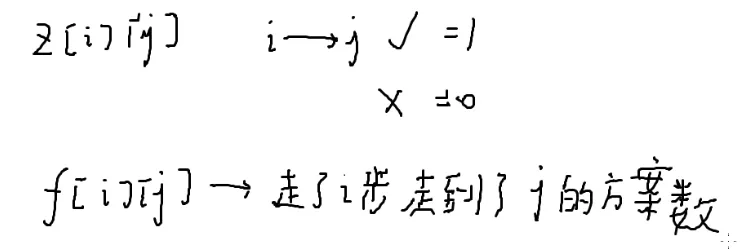
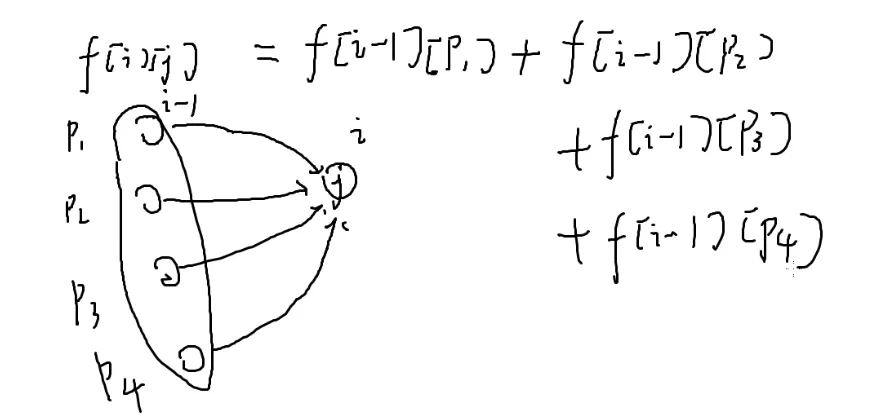
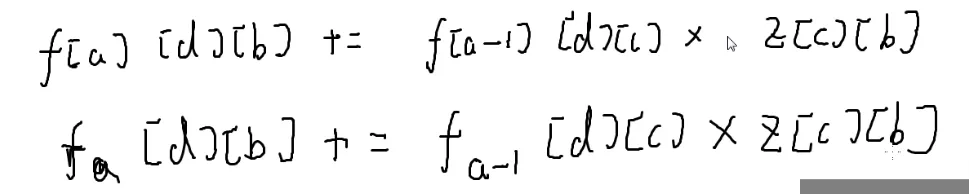



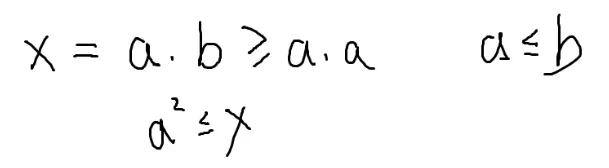
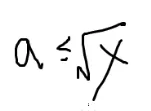
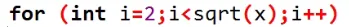

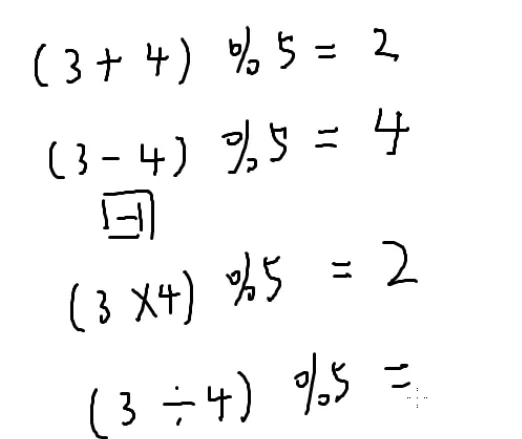
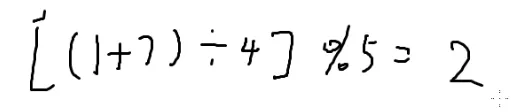
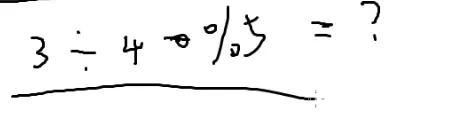
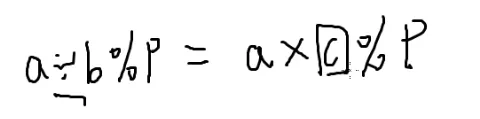
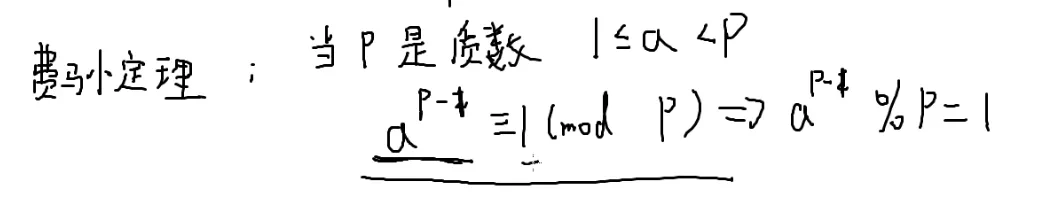
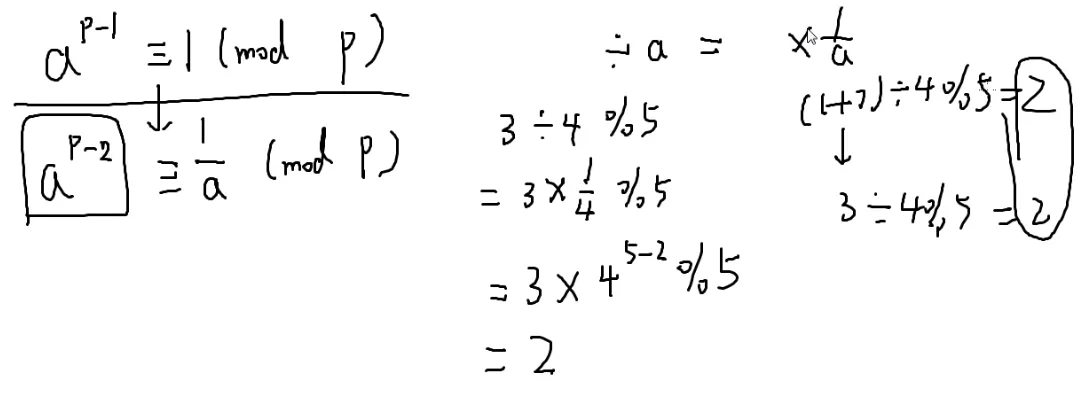
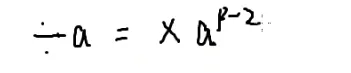

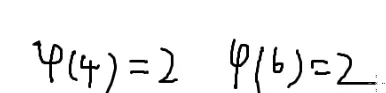
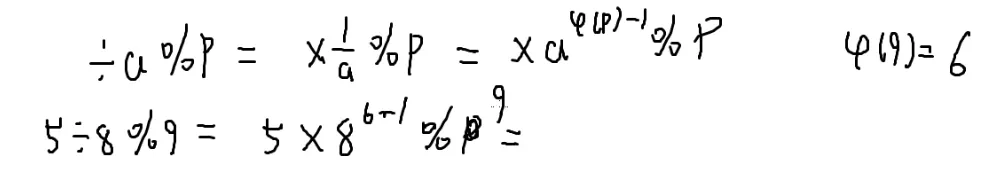
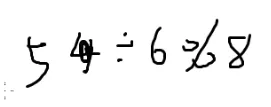
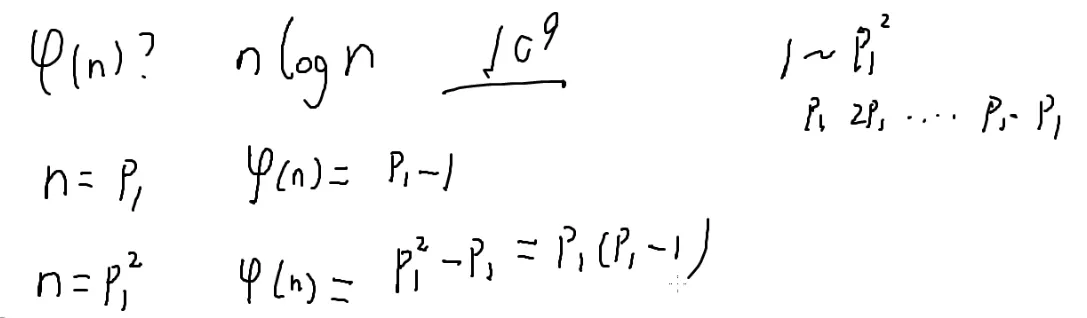
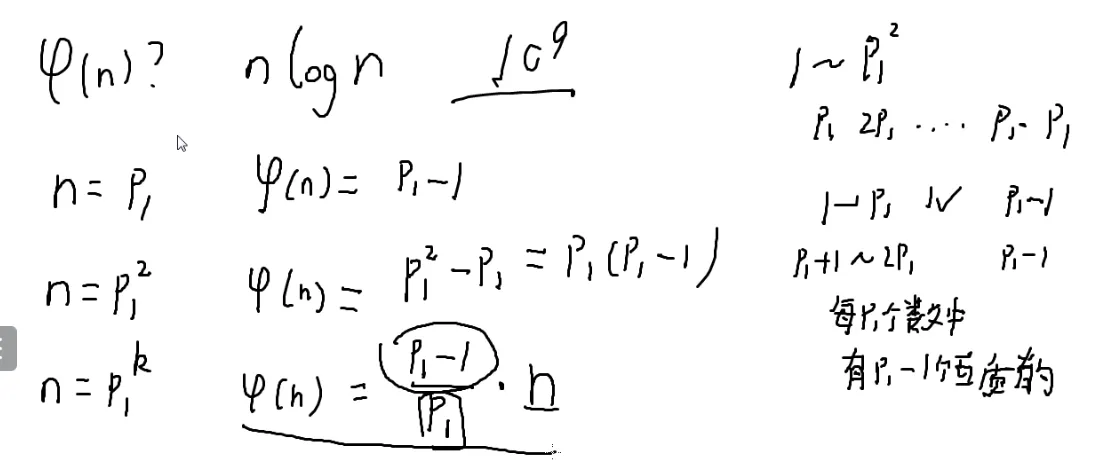
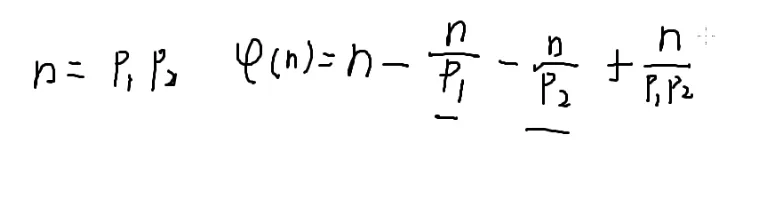
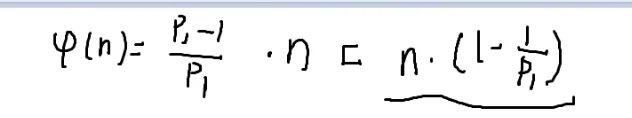
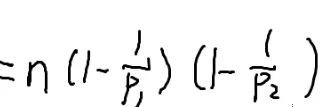
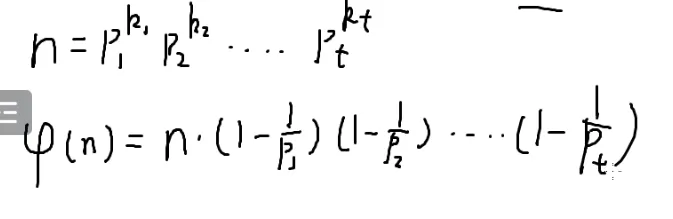
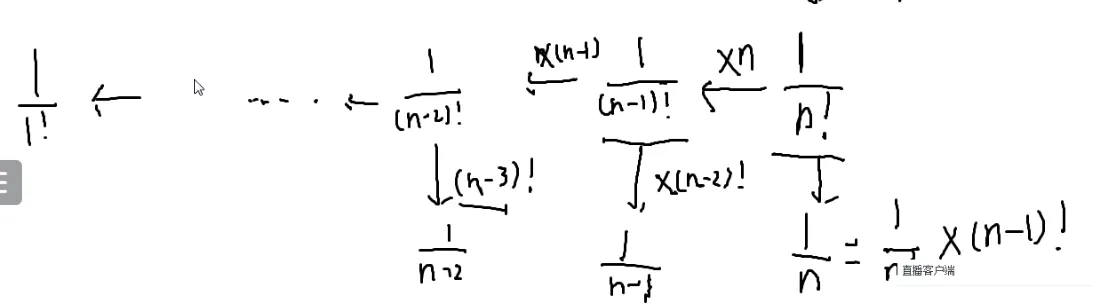
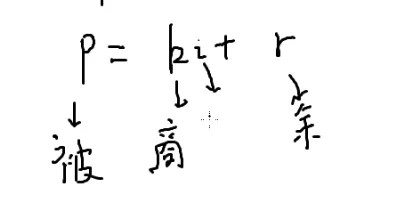
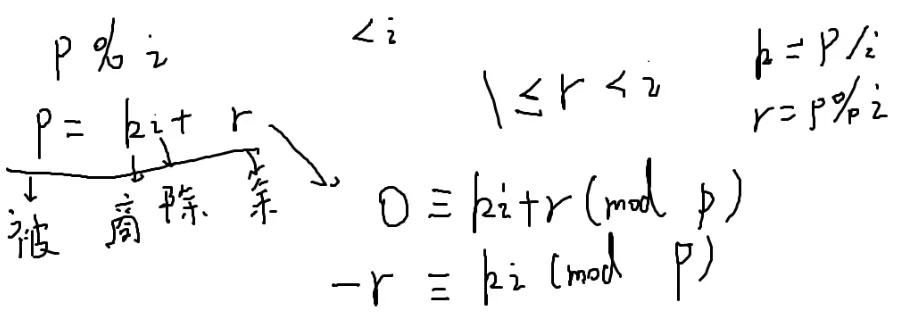
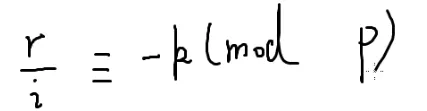
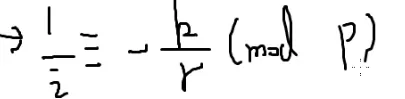
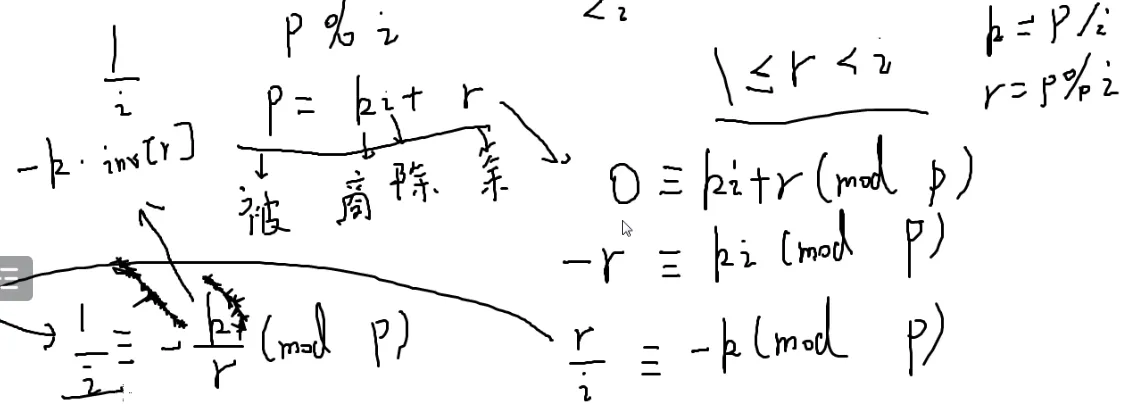

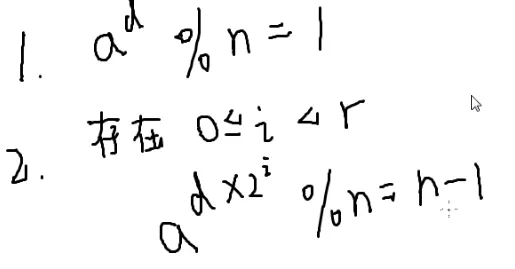

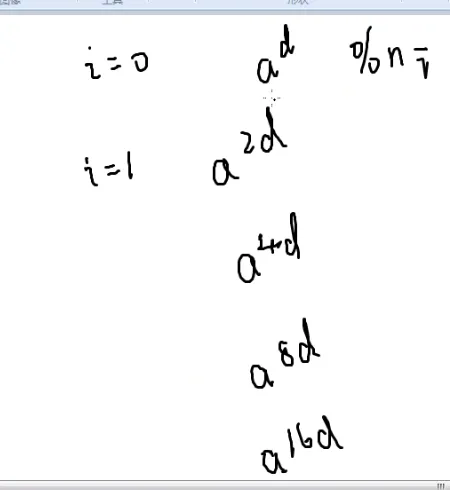
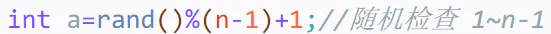
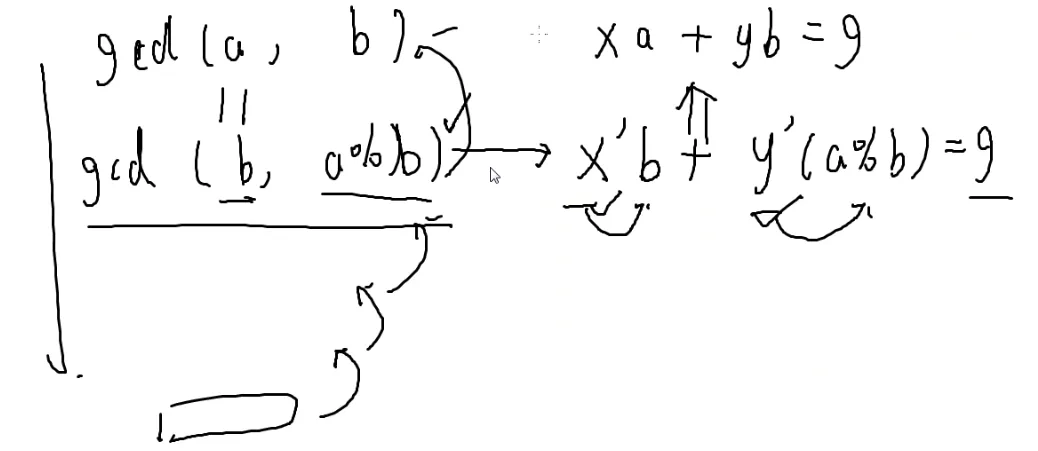
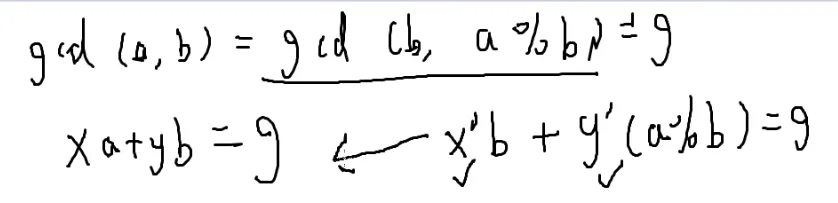
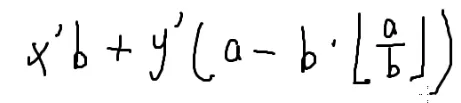
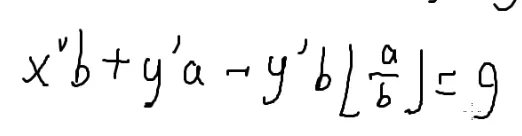
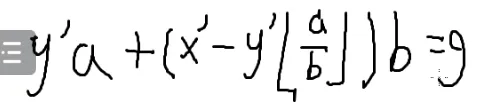
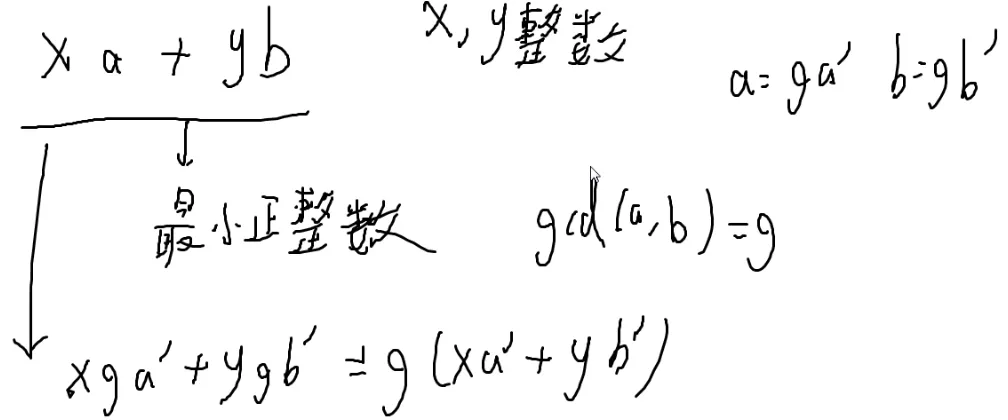
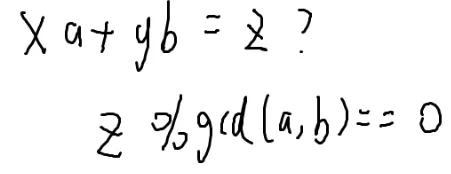
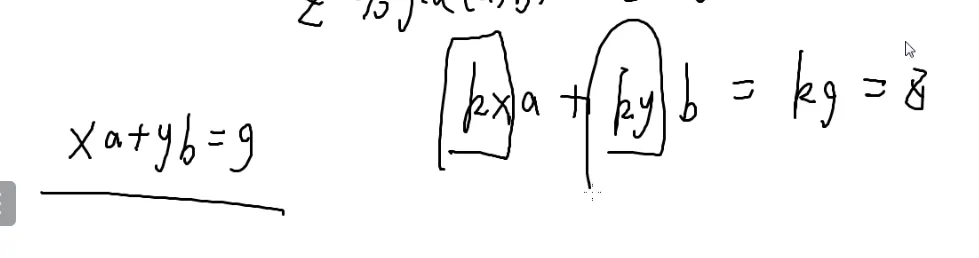
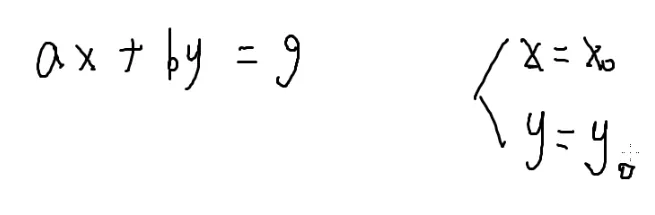
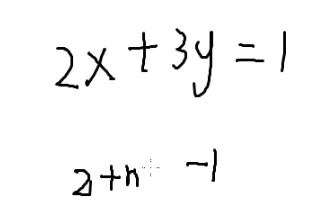
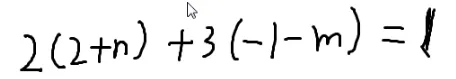
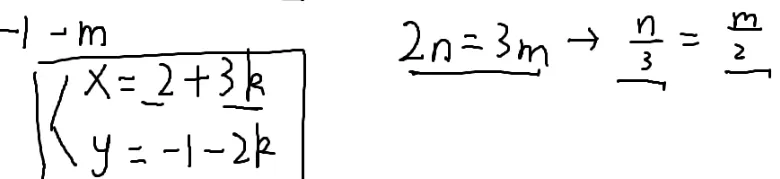
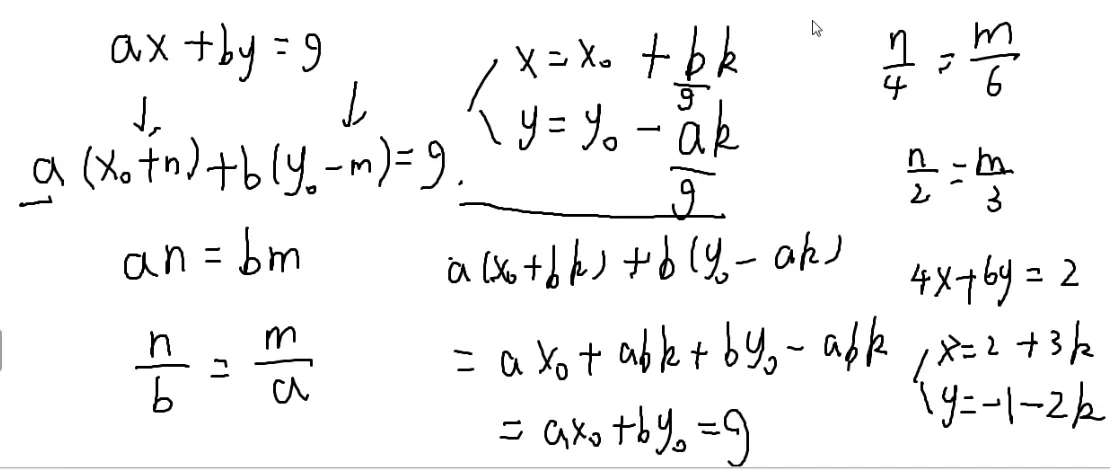
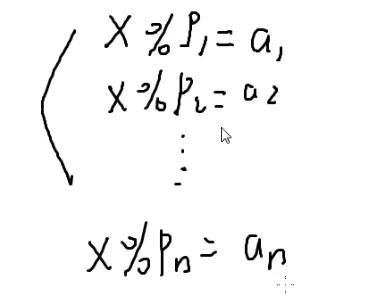
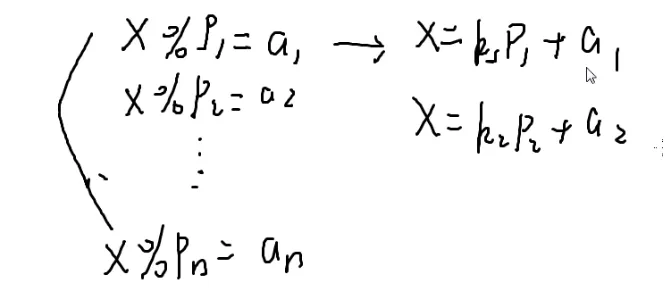
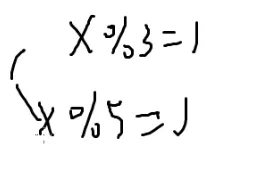
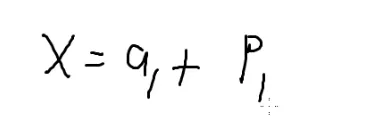

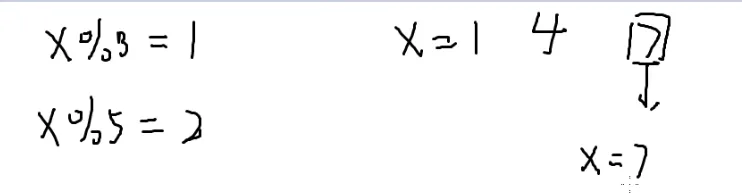

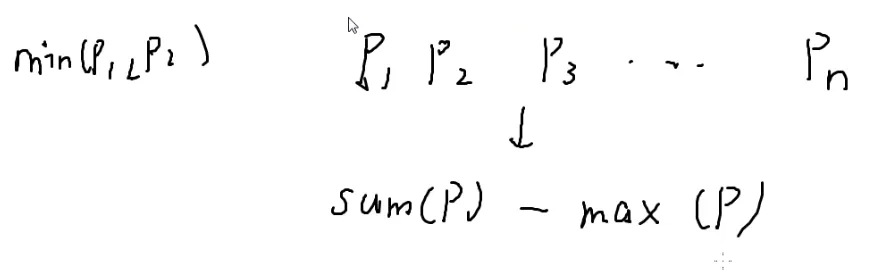
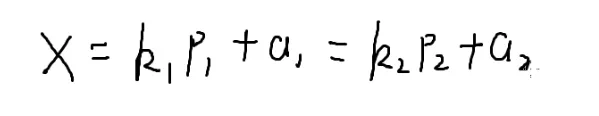
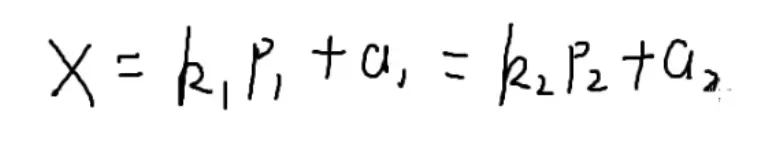
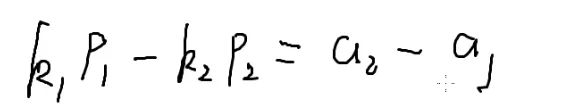
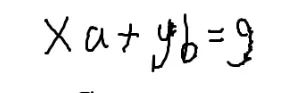
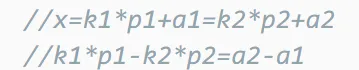
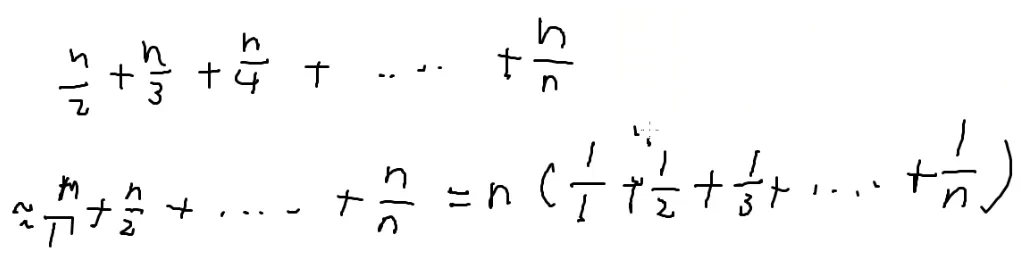

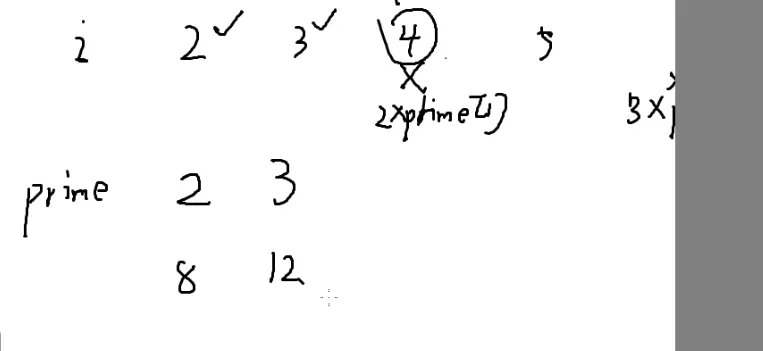

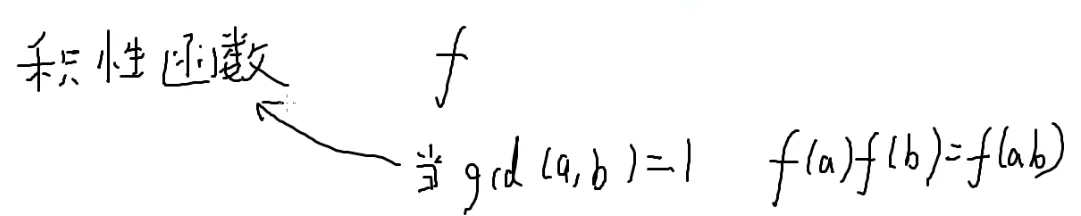
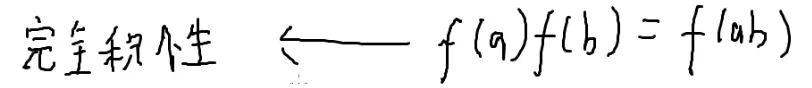
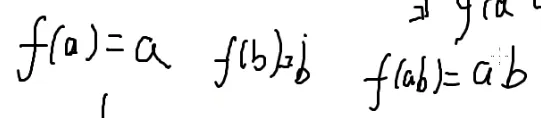
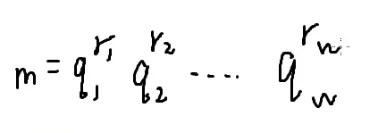
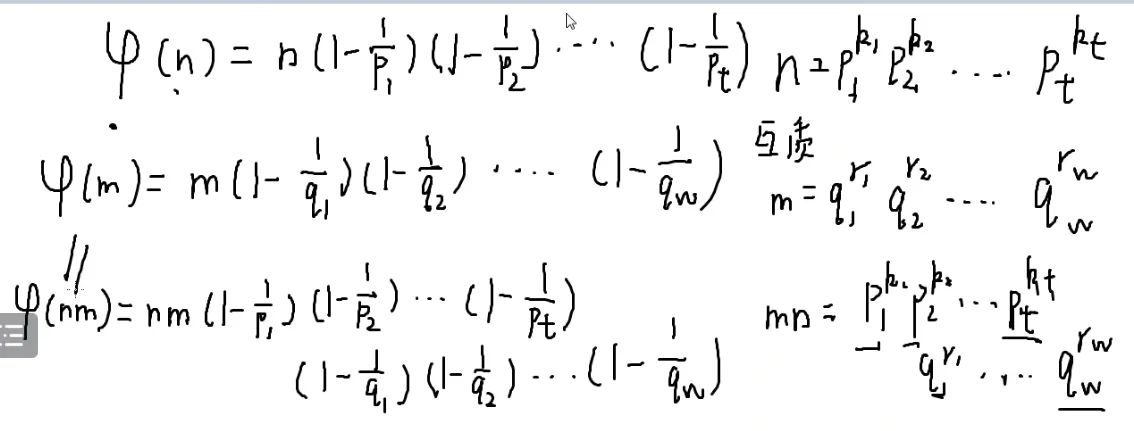
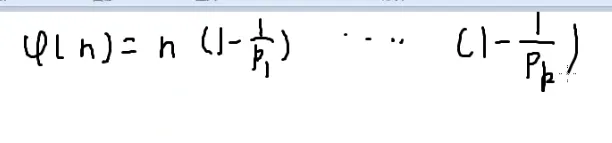
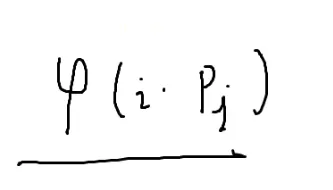
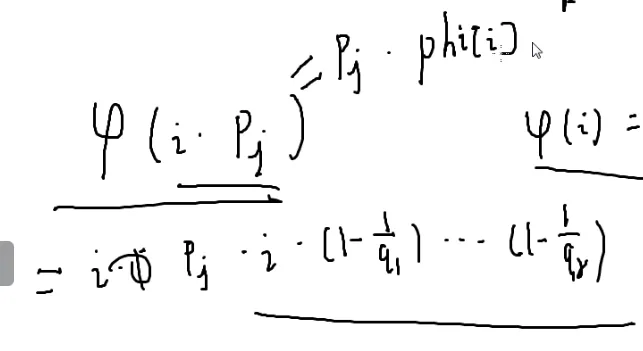
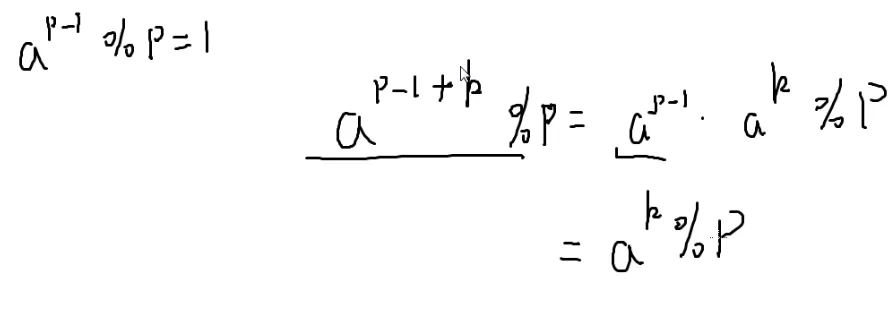

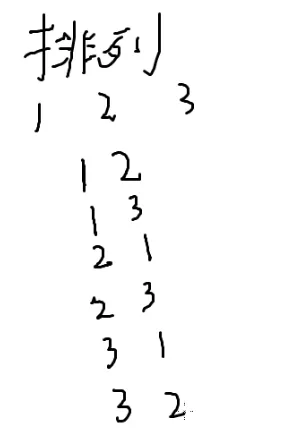
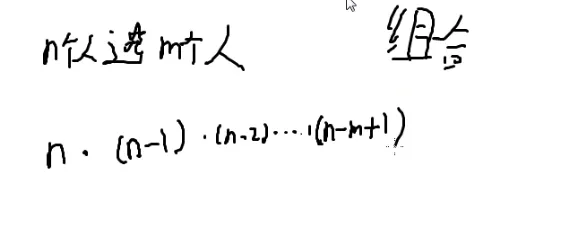

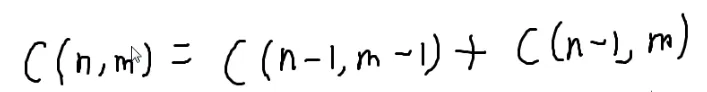
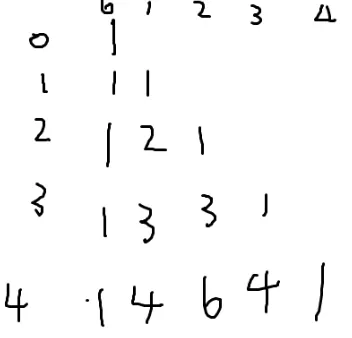
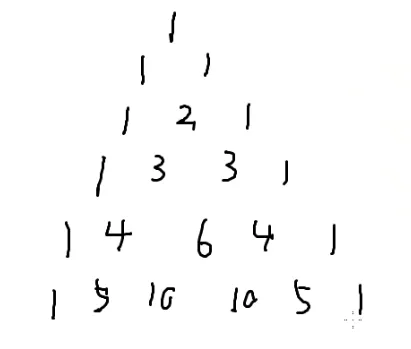
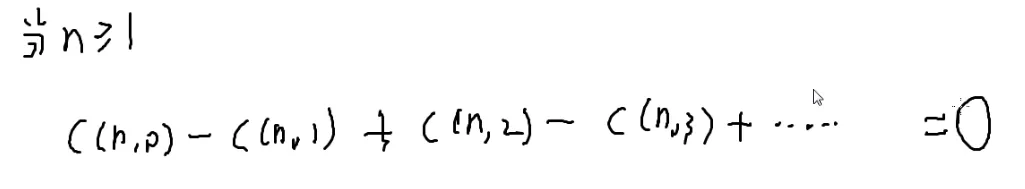
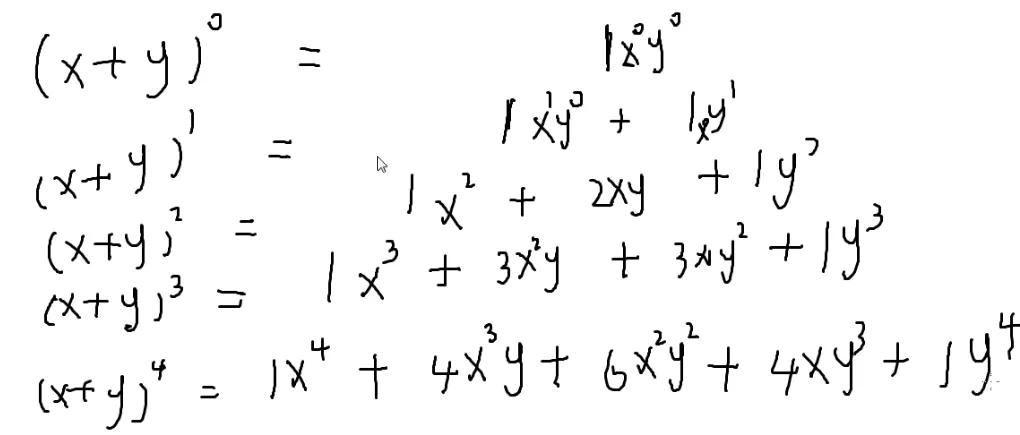
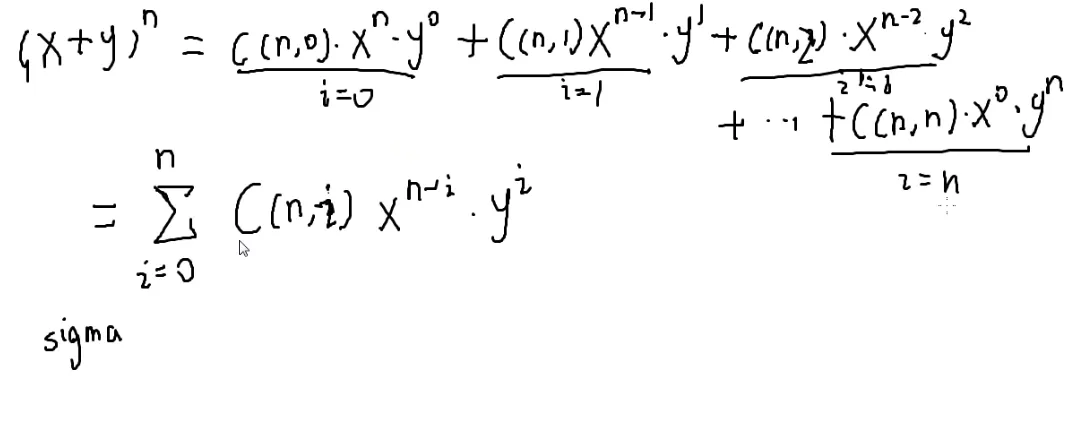
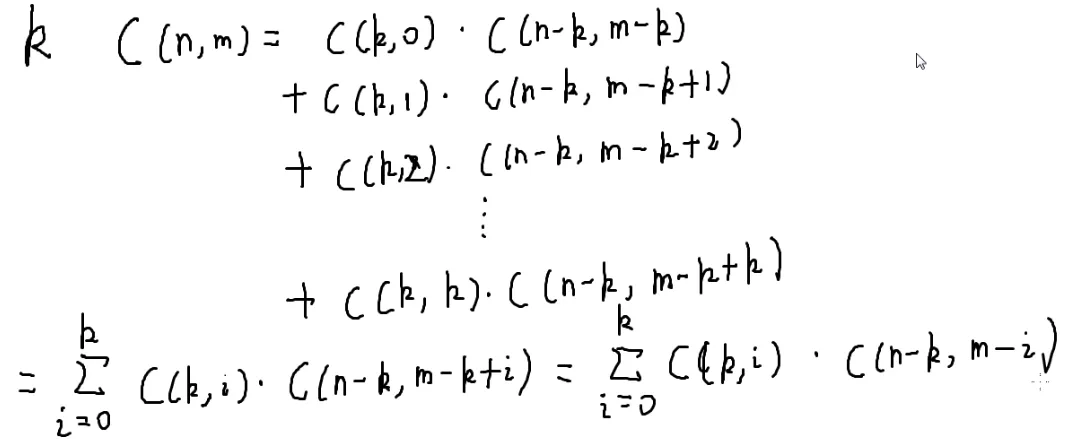

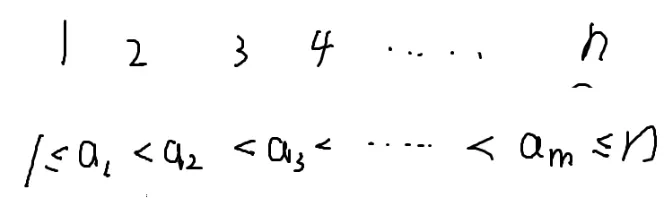
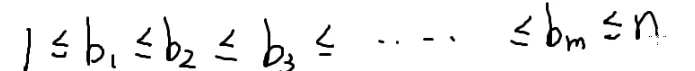
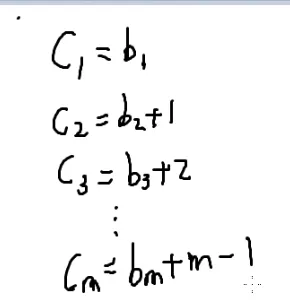
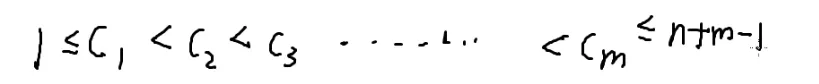
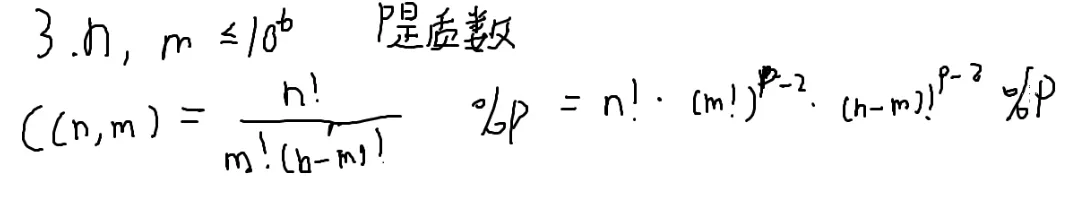
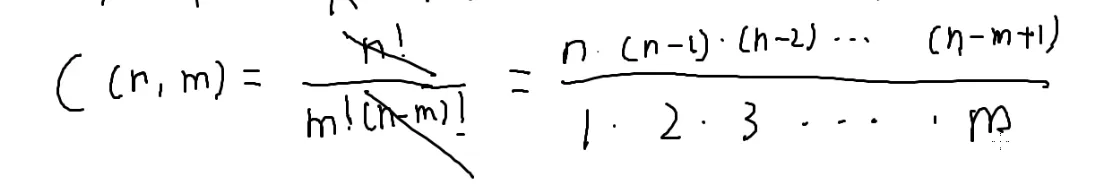

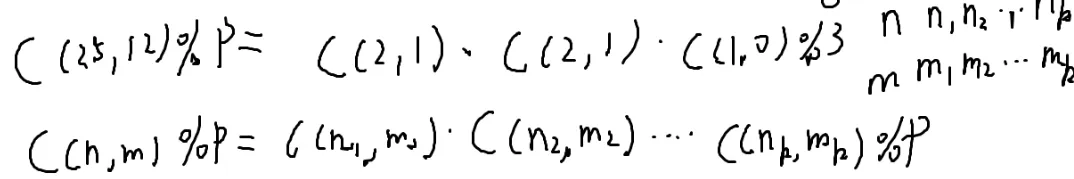
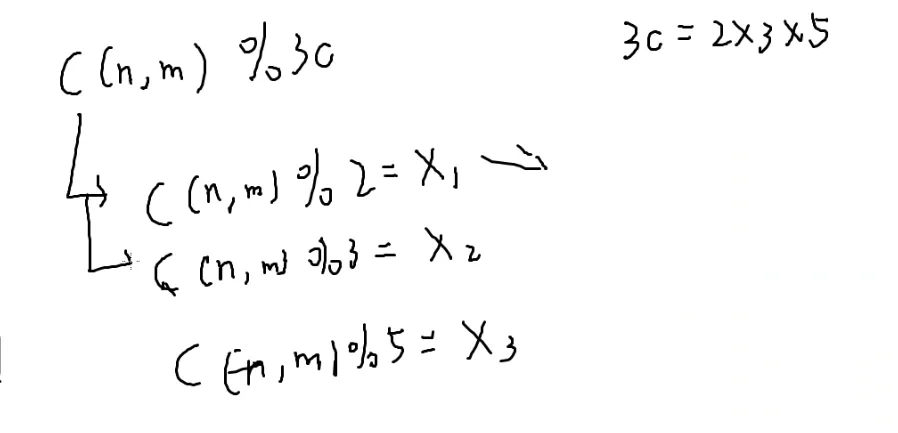

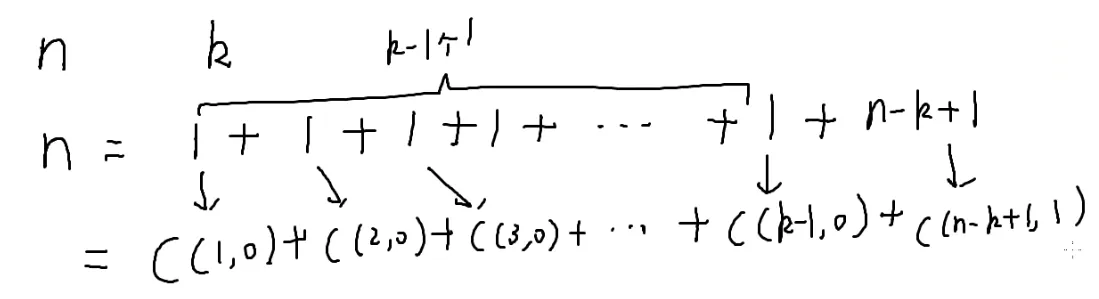
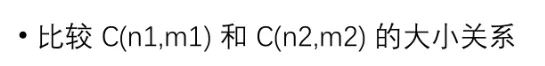

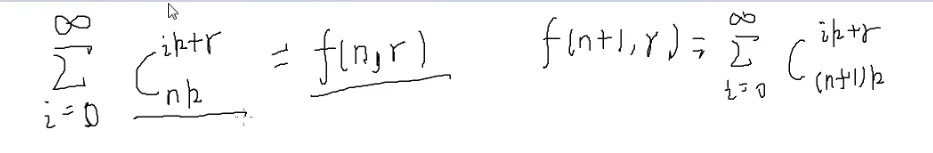 ^1121
^1121